Standard system resource limits are set up so that each process receives the same process-based limits at the time the process is created. While limits on individual processes are useful, they do not restrict individual users to a given share of the system. With the IRIX kernel job limits feature, all processes associated with a particular login session or batch submission are encapsulated as a single logical unit called a job. The job is the container used to group processes by login session. Limits on resource usage are applied on a per user basis for a particular job and these limits are enforced by the kernel. All processes are associated with a particular job and are identified by a unique job identifier (job ID). The processes belonging to a particular job can be limited, controlled, queried, and accounted for as a unit. This allows a system administrator to set job-specific limits on CPU time, memory, file space, and other system resources. The user limits database (ULDB) allows user-specific limits for jobs. If no ULDB is defined, job limits are the same for all jobs. Job limits software can help maximize utilization of larger systems in a multiuser environment.
| Note: Job limit values (rlim_t) are 64-bit in both n32 and n64 binaries. Consequently, n32 binaries can set 64-bit limits. o32 binaries cannot set 64-bit limits because rlim_t is 32-bits in o32 binaries. IRIX supports three Application Binary Interfaces (ABIs): o32, n64, and n32 (for more information on ABIs, see the abi(5) man page).
For more information on rlimit_* values, see “Using systune to Display and Set Process Limits” in Chapter 1 and “showlimits”. |
This chapter contains the following sections:
The sections in this chapter contain information about installing job limits software on your system. You should reference them in the order they are listed here:
For a general description of jobs and job limits, see “Job Limits Overview”, and “Job Limits Supported”.
To install the job limits package, see “Installing Job Limits”.
For information about writing a user limits directives input file infile and creating the user limits database (ULDB), see “Creating the User Limits Directives Input File”, and “Creating the User Limits Database”, respectively.
For a list of man pages related to job limits, see “Job Limits Man Pages”.
For information on how to use the systune joblimits command to set systemwide default values for job limits, see “Using systune to Display and Set Job Limits”.
For information on how to view job limits on a system, see “User Commands for Viewing and Setting Job Limits”.
For information on troubleshooting your job limits installation, see “Troubleshooting Job Limits”.
For information on application programming interfaces, see “Application Programming Interface for Job Limits” in Appendix A, and “Application Programming Interface for the ULDB” in Appendix A.
Job limits software helps ensure that each user has access to the appropriate amount of system resources such as CPU time and memory and makes sure that users do not exceed their allotted amount. Job limits software can improve system throughput and utilization by restricting how much of a machine each user can use. For information on user-based job limits supported in IRIX, see “Job Limits Supported”.
Work on a machine is submitted in a variety of ways, such as an interactive login, a submission from a workload management system, a cron job, or a remote access such as rsh, rcp, or array services. Each of these points of entry create an original shell process and multiple processes flow from that original point of entry. The kernel job provides a means to limit the resource usage of all the processes resulting from a point of entry. A job is a group of related processes all descended from a point of entry process and identified by a unique job ID. A job can contain multiple process groups, sessions, or array sessions and all processes in one of these subgroups are always contained within one job. Figure 2-1, shows the point of entry processes that initiate the creation of jobs.
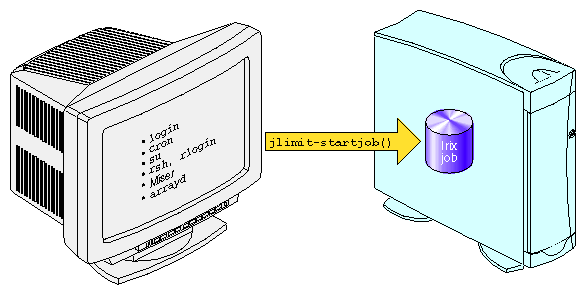
IRIX job limits have the following characteristics:
A job is an inescapable container. A process cannot leave the job nor can a new process be created outside the job without explicit action, that is, a system call with root privilege.
Each new process inherits the job ID and limits from its parent process.
All point of entry processes (job initiators) create a new job and set the job limits appropriately.
Users can raise and lower their own job limits within maximum values specified by the system administrator.
The job initiator performs authentication and security checks.
The process control initialization process (init(1M)) and startup scripts called by init are not part of a job and have a job ID of zero.
| Note: The upper bits of the job ID are used to indicate the machine ID. The job ID contains the array services machine ID (asmchid). Array services are started by the init process and large job IDs are created. To the administrator, this may seem like large job ID values appear without explanation because they have not set the machine ID. For more information on the asmchid parameter, see Appendix A, “IRIX Kernel Tunable Parameters”, in the IRIX Admin: System Configuration and Operation and the arsctl(2) and newarraysess(2) man pages. |
| Note: The existing IRIX commands jobs(1), fg(1), and bg(1) man pages apply to shell “jobs” and are not related to IRIX kernel job limits. |
| Note: Job initiators like secure shell that are not developed by SGI might not initiate an IRIX kernel job. |
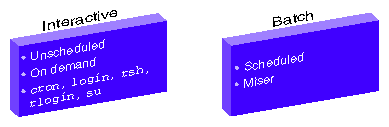
Figure 2-2 shows two limit domains. Limit domains are a way to categorize work. The job initiators shown in Figure 2-1, can be categorized as either interactive or batch processes. Limit domain names are defined by the system administrator when the user limits database (ULDB) is created. Applications that use the ULDB to retrieve job limits information expect to find limit information with specific names. These names are defined by convention. For additional information on limit domains and the ULDB, see “User Limits Database”.
The IRIX operating system provides a number of commands that provide information about the memory usage on a system. The job limits jstat(1) command reports the current usage and highwater memory values of all concurrently running processes within a job. For more information on memory usage in IRIX, see Chapter 6, “IRIX Memory Usage”. For more information on the jstat(1) command, see “jstat”.
Table 2-1 shows job limits supported by the IRIX operating system. Each limit restricts the use of a particular system resource for all the processes contained within a job. Job limits software also introduces a limit unique to jobs called JLIMIT_NUMPROC that controls the number of processes in a job.
Limit Name | Symbolic ID | Units | Description | Enforcement |
|---|---|---|---|---|
jlimit_nproc_cur | JLIMIT_NUMPROC | processes | Maximum number of processes within the job | Process creation by any job fails with errno set to EAGAIN |
jlimit_nofile_cur | JLIMIT_NOFILE | file descriptors | Maximum total number of open file descriptors all processes in job can have | open(2) calls by any job fail with errno set to EMFILE |
jlimit_rss_cur | JLIMIT_RSS | bytes | Maximum total resident set size for all processes in a job | Resident pages above limit become prime swap candidates |
jlimit_vmem_cur | JLIMIT_VMEM | bytes | Maximum total address space for all processes in a job | The brk(2) and mmap(2) calls in any job fail with errno set to ENOMEM |
jlimit_data_cur | JLIMIT_DATA | bytes | Maximum total heap size for all processes in job | The brk(2) calls in any job fail with errno set to ENOMEM |
jlimit_cpu_cur | JLIMIT_CPU | seconds | Maximum number of CPU seconds allowed for all processes in a job. | Termination of all processes in a job that continue to consume CPU time via SIGXCPU signal. See Note below. You can also use the cpulimit_gracetime parameter to alter signalling behavior, see “cpulimit_gracetime”. |
jlimit_pmem_cur | JLIMIT_PMEM | bytes | Maximum total resident set size for all processes in a job. | Termination of all processes in job that continue to consume system resources via SIGKILL signal. See Note below and “cpulimit_gracetime”. |
Limits on the consumption of system resources by a job, shown in Table 2-1, may be obtained with the getjlimit(2) function and set by the setjlimit(2) function. The getjlimit function gets the current and maximum job limits values for the specified job. The CAP_MAC_READ capability is needed to retrieve values from jobs belonging to other users.
The setjlimit(2) function sets the current and maximum job limits values for the specified job. If the current job is different from the job being requested, the setjlimit function checks for the CAP_MAC_WRITE capability. If the maximum (hard) limits are being raised, the setjlimit function checks for the CAP_PROC_MGT capability.
For additional information, see the getjlimit(2) man page. For more information on the capability mechanism that provides fine grained control over the privileges of a process, see the capability(4) and capabilities(4) man pages.
The waitjob mechanism allows a batch processing system to find out job limit information for jobs that exit abnormally. The waitjob function obtains information about a terminated job that has been set with setwaitjobpid argument to wait. For more information on the waitjob(2) and setwaitjobpid(2) calls, see “Application Programming Interface for Job Limits” in Appendix A and “Application Programming Interface for the ULDB” in Appendix A, respectively, and the waitjob(2) and setwaitjobpid(2) man pages.
You can use the systune joblimits command to set system-wide defaults. For additional information, see “Using systune to Display and Set Job Limits” and the systune(1M) man page.
The cpulimit_gracetime parameter establishes a grace period for processes that exceed the CPU time limit. Each process in a job has a cpulimit_gracetime associated with it. If the cpulimit_gracetime parameter is set to 10 seconds and a job has 100 processes, theoretically, a job could run for an additional 1000 seconds after the JLIMIT_CPU limit had been exceeded. The cpulimit_gracetime parameter controls the signalling behavior associated with the CPU limit. For additional information on the cpulimit_gracetime parameter, see “Additional Process Limits Parameters” in Chapter 1.
Job limits software works in a manner similar to process limits when dealing with the cpulimit_gracetime. As a process executes, the CPU usage increases. When the limit is reached, the SIGXCPU signal is sent individually to each process when it executes. When the SIGXCPU is sent to a process, the grace period goes into effect for that process. If the process is still executing when the grace period expires, it is terminated with the SIGKILL signal. Only the processes in a job that are executing, are sent a SIGXCPU signal. Each process in a job gets an individual grace period. Therefore, the SIGXCPU signal is not sent en masse to all processes in a job.
| Note: Only processes in a job that are executing and consuming system resources, such as CPU time or memory, when a clock interrupt occurs and a JLIMIT_CPU or JLIMIT_PMEM limit has been exceeded, will receive either a SIGXCPU or SIGKILL signal, respectively. It is possible that processes in a job that are idle will not be signalled even if a limit has been exceeded. |
The User Limits Database (ULDB) contains job limits information which allows a system administrator to control access to a machine on a per user basis. Job initiators, the applications that initiate new jobs on the system like login, rsh, rlogin, cron, and workload management systems like Miser, retrieve job limits values from the ULDB for a particular user and use the information to set limits, appropriately.
For more information on job initiators, see “Job Limits Overview”.
The ULDB is used to set job limit and process limit values for jobs when the job limits package is installed. If job limits are not installed, process limits are handled by the current resource limits functionality.
Domain defaults apply to all users unless there is a "user" entry that describes values for that user. User specific values override the domain defaults. Values in the ULDB override the system default values for both job limits and process limits.
This section describes the commands used to create, maintain, and display the contents of the ULDB and the library application programming interface (API), which allows applications access to the ULDB information.
| Note: The ULDB configuration file contained in the /etc/jlimits.in file contains a template you can follow when setting up the ULDB on your system. |
The /etc directory also contains the jlimits and jlimits.m files. The jlimits.in file is parsed into the colon delimited jlimits file, which is used to load job limits into the local ULDB jlimits.m file or into the NIS master map. The jlimits file is automatically generated by the genlimits(1M) command. The jlimits.m file is the local ULDB mdbm file.
The command to create the ULDB is as follows:
genlimits [-i infile] [-l] [-m] [-L local_database] [-N nisfile] [-v] |
The genlimits command parses the formatted ASCII user limits directives input file (infile) into a colon-delimited ASCII file, which can be used to create one of the following output formats:
Network Information Service (NIS) master server map (-m option)
Local database for NIS or direct (non-NIS) use (-l option)
The genlimits command accepts the following options:
| -i infile | Identifies the location of the user limits directives input file. If you do not specify the -i option, the default file is /etc/jlimits.in. | |
| -l | Creates a local database for Network Information Service (NIS) or direct (non-NIS) use. When NIS is enabled, the local database contains local entries which override or supplement entries from the NIS server. When NIS is not enabled, the local database contains information to set limits on the system. By default, this database is in the /etc/jlimits.m file. You cannot use the -l option with the -m option. | |
| -m | Creates the NIS master server map. It generates and stores the map in the standard NIS map location. You cannot override this location. You cannot use the -m option with the -l option. | |
| -L local_database | Specifies an alternate location for the local database. The -L option works in conjunction with the -l option. | |
| -N nisfile | Specifies a different location for the created NIS database source input file. The default location is the /etc/jlimits file. You can use the -N nisfile option to create a new database without overwriting the existing /etc/jlimits file. | |
| -v | Specifies verbose mode, which prints out messages describing actions of the genlimits command. |
For additional information, see the genlimits(1M) man page.
The user limits directive file contains the input to the genlimits(1M) command, defining the information on domains, limits, and users that will be used to generate the ULDB. This section describes how to write a user limits directives input file.
Numeric values can have a letter appended that indicate a multiplier that is applied to the numeric value provided to determine the limit value as follows:
| Letter | Multiplier Value | |
| k (kilo) | 1024 (2**10) | |
| m (mega) | 1,048,576 (2**20) | |
| g (giga) | 1,073,741,824 (2**30) | |
| t (tera) | 1,099,511,627,776 (2**40) | |
| H (hours) | 3600 | |
| M (minutes) | 60 |
Use the k, m, g, and t multipliers when defining memory limits or other large values.
Use the H and M multipliers when defining time values.
Multiplier values are defined in the /usr/include/uldb.h system include file.
There are no requirements that multipliers be use in the above manner.
Numeric limit values can also be specified as “unlimited” which indicates there is no upper limit for this particular limit type.
For additional information about creating the ULDB, see the genlimits(1M) man page.
Each limit domain that is referenced in the ULDB must first be identified using the "domain" directive. The directive provides the ASCII domain name and a list of the default limit values for the domain. An example domain directive follows:
domain domain_name {
limit_name = value
limit_name:machname = value
...
} |
Certain domain names are reserved for user job limits. Other domain names may be created and used for special purposes. The following list contains reserved domain names:
| Reserved Domain Name | Description |
| interactive | Used by interactive job initiators such as telnet and login |
| batch | A generic batch domain used as secondary choice for all workload management software |
| miser | The domain used when submitting work to Miser |
| nqe | The domain used when submitting work to NQE |
| lsf | The domain used when submitting work to LSF |
The "user" directive specifies a set of limits for an individual user. The user name must identify a valid login account. The uid value is optional. If uid is specified, the genlimits command verifies that the uid provided matches the uid defined for the user on the machine where genlimits executes. Domain clauses identify each domain for which the user will have unique limit values. The domain listed in the user directive must already be defined in a prior domain directive. The syntax and semantics of the domain clause is the same as the domain directive. It is not necessary to provide user directives for all users on the system. If there is no user directive for a queried user or there are no values for a queried domain, the default values for that domain are returned. An example user directive follows:
user user_name[:uid] {
domain_name {
limit_name = value
limit_name:machname = value
...
}
domain_name {
...
}
...
} |
The limit specifications for both the domain and user directives may include an optional machine name. Limit values specified with a machine name apply only to that machine. Limits without a machine name apply to all machines in the cluster. The directives input file can contain several occurrences of the same limit, each with a different name, as well as an occurrence without a machine name specified.
The genlimits command processes limit values with associated machine names differently depending on the type of database (see “Creating the User Limits Database”) being generated:
If the -m option is used to generate a NIS master map, limit values with associated machine names are ignored. Only clusterwide values without machine names are included in the database.
If the -l option is used to generate a local database, the genlimits command selects the limit value with the name of the local machine if present. If there is no limit value with the local machine name, the genlimits command selects the clusterwide value with no machine name. You can determine the local machine name by running the uname -n command. For additional information on the uname command, see the uname(1) man page.
Because the ULDB is completely rebuilt whenever the genlimits command is invoked, the input directive file must contain a complete representation of the database. When changes are needed, the system administrator must edit the user limits directives input file and then rebuild the database. Because domain defaults are used if there is no user entry for a particular user, the administrator only needs to provide user entries for named users to overwrite default values. The following example shows a user limits directives input file that specifies three limit types, two domains, and one user with individual limits. The ULDB only stores the limit values. The meaning of a value and the units it expresses are up to the application that uses the limit.
| Note: If you are updating entries in the ULDB and they do not change the job limit values on your system, make sure that limit names used in the ULDB and limit names used in the systune joblimits group are exactly the same. For additional information, see “Troubleshooting Job Limits”. |
domain interactive { # domain for interactive logins
jlimit_cpu_cur = 60
jlimit_cpu_max = 120 # limit interactive jobs to 120 CPU seconds
jlimit_vmem_cur = 2m
jlimit_vmem_max = 4m # limit interactive jobs to 4 megabytes of virtual memory
jlimit_numproc_cur =10
jlimit_numproc_max = 20 # limit interactive jobs to 20 concurrent processes
}
domain batch { # domain for batch submissions
jlimit_cpu_cur = 3600
jlimit_cpu_max = 7200 # limit batch jobs to two hours of CPU time
jlimit_vmem_cur = 128m
jlimit_vmem_max = 256m # limit batch jobs to 256 megabytes of memory
jlimit_numproc_cur = unlimited
jlimit_numproc_max = unlimited # no limit on processes in a batch job
}
user fred:123 { # User "fred" gets his own interactive CPU limits
interactive { #
jlimit_cpu_cur = 300
jlimit_cpu_max = 600 # "fred" needs to run longer jobs in interactive mode
}
} |
You can use the systune joblimits command to view and set systemwide default values for user job limits. The ULDB will override these values if it exists. The joblimits group contains the following variables:
jlimit_cpu_cur
jlimit_cpu_max
jlimit_data_cur
jlimit_data_max
jlimit_vmem_cur
jlimit_vmem_max
jlimit_rss_cur
jlimit_rss_max
jlimit_nofile_cur
jlimit_nofile_max
jlimit_numproc_cur
jlimit_numproc_max
jlimit_pmem_cur
jlimit_pmem_max |
Output from the systune joblimits command follows:
$ systune joblimits
group: joblimits (statically changeable)
jlimit_numproc_max = 1024 (0x400) ll
jlimit_numproc_cur = 1024 (0x400) ll
jlimit_nofile_max = 5000 (0x1388) ll
jlimit_nofile_cur = 400 (0x190) ll
jlimit_rss_max = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_rss_cur = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_vmem_max = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_vmem_cur = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_data_max = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_data_cur = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_cpu_max = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_cpu_cur = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_pmem_max = 9223372036854775807 (0x7fffffffffffffff) ll
jlimit_pmem_cur = 9223372036854775807 (0x7fffffffffffffff) ll
|
The display information is described below:
jlimit_numproc - Number of processes limit
jlimit_nofile - Number of files limit
jlimit_rss - Resident set size, default is in bytes
jlimit_vmem - Virtual memory limit, default is in bytes
jlimit_data - Data size, default is in bytes
jlimit_cpu - CPU time, default in seconds.
jlimit_pmem - Maximum resident set size for all processes in a job, default in bytes
For additional information, see the systune(1M) and jlimit(1) man pages.
This section describes the following user commands which can be used to view and set job limits:
The command to view limit information from the ULDB is as follows:
showlimits [-D] [-d] [-u user_name] [domain_name] |
The showlimits command displays limits information from the user limits database (ULDB).
The showlimits command accepts the following options:
| -D | Displays the names of all the domains defined in the ULDB. When you specify the -D option, the domain name and other options are ignored. | |
| -d | Displays the domain default limits. When no options are specified, the showlimits command displays the default limits for all domains. | |
| -u user_name | Displays the limits values for the specified user rather than the current user. | |
| domain_name | Displays the limits values for the specified domain rather than all domains. |
If no options are specified, the showlimits command displays the current limits information for the current user for all domains as shown below:
% showlimits
Domain interactive:
jlimit_cpu_cur: unlimited
jlimit_cpu_max: unlimited
jlimit_data_cur: unlimited
jlimit_data_max: unlimited
jlimit_nofile_cur: 400
jlimit_nofile_max: unlimited
jlimit_vmem_cur: unlimited
jlimit_vmem_max: unlimited
jlimit_rss_cur: unlimited
jlimit_rss_max: unlimited
jlimit_pthread_cur: 2k
jlimit_pthread_max: 65535
jlimit_numproc_cur: 1k
jlimit_numproc_max: 65535
rlimit_cpu_cur: unlimited
rlimit_cpu_max: unlimited
rlimit_fsize_cur: unlimited
rlimit_fsize_max: unlimited
rlimit_data_max: unlimited
rlimit_stack_cur: 64m
rlimit_stack_max: unlimited
rlimit_core_cur: unlimited
rlimit_core_max: unlimited
rlimit_nofile_cur: 200
rlimit_nofile_max: unlimited
rlimit_vmem_max: unlimited
rlimit_rss_max: unlimited
Domain batch:
jlimit_cpu_cur: unlimited
jlimit_cpu_max: unlimited
jlimit_data_cur: unlimited
jlimit_data_max: unlimited
jlimit_nofile_cur: 400
jlimit_nofile_max: unlimited
jlimit_vmem_cur: unlimited
jlimit_vmem_max: unlimited
jlimit_rss_cur: unlimited
jlimit_rss_max: unlimited
jlimit_pthread_cur: 2k
jlimit_pthread_max: 65535
jlimit_numproc_cur: 1k
jlimit_numproc_max: 65535
rlimit_cpu_cur: unlimited
rlimit_cpu_max: unlimited
rlimit_fsize_cur: unlimited
rlimit_fsize_max: unlimited
rlimit_data_max: unlimited
rlimit_stack_cur: 64m
rlimit_stack_max: unlimited
rlimit_core_cur: unlimited
rlimit_core_max: unlimited
rlimit_nofile_cur: 200
rlimit_nofile_max: unlimited
rlimit_vmem_max: unlimited
rlimit_rss_max: unlimited
|
| Note: If the ULDB has changed after the user logged in, the current limits will not be effective. Current limits will be effective for any new users that login. |
For a description of the job limit values, see Table 2-1. For a description of the process limit values, see Table 1-1.
For additional information, see the showlimits(1) man page.
The command to display and set job limits is as follows:
jlimit [-j job_id] [-h] [limit_name [value]] |
The jlimit command displays and changes limits on job resource usage. The current and maximum (hard) limits are set when a job starts from values that are contained in the user limits database (ULDB) information for the user. You can raise and lower your current limits within the range not to exceed your maximum limit. You can irrevocably lower your maximum limit. You must have the CAP_PROC_MGT capability to raise your maximum limit. Limit enforcement always occurs at the current limit regardless of your maximum limit value. See the capability(4) and capabilities(4) man pages for additional information on the capability mechanism that provides fine grained control over the privileges of a process.
The jlimit command accepts the following options:
| -j job_id | Specifies a particular job ID for a job where limits are going to be changed. You must have the CAP_MAC_WRITE and CAP_PROC_MGT capabilities to change job limits for jobs that belong to other users. The job ID is printed out in hexadecimal. When the job ID is specified, the "0x" prefix is optional. | |
| -h | Specifies that the maximum (hard) limit values for a job are displayed or modified. If you do not specify the -h option, the jlimit command displays or modifies current limit values. | |
| limit_name [value] | Displays or sets the value for the specified limit:
|
If the -j option with a job_id argument is specified, the jlimit command prints out the following information:
% jlimit -j 0x14
cputime: unlimited
datasize: unlimited
files: unlimited
vmemory: unlimited
ressetsize: unlimited
processes: 65535 |
For an explanation of the limit values, see Table 2-1.
For additional information, see the jlimit(1) man page.
The command to display job status information for active jobs is as follows:
jstat [-a] [-l] [-p] jstat [-j job_id] [-l] [-p] |
The jstat command accepts the following options:
| -a | Displays information about all jobs. | |
| -j job_id | Displays information only for the specified job ID (job_id). | |
| -l | Displays limit information about the current or specified job including the current usage, current limit, and maximum limit. | |
| -p | Displays information about each process that belongs to the current or specified job including the process ID, state, and executing command. | |
| -P | Displays the memory limits information in pages rather than in bytes. This option is used with the -l option. |
If neither the -a or -j job_id are used, the jstat command displays information on the current job.
If the -l option is specified, the jstat command prints out the current usage, high usage, current limit, and maximum limit information for the current job as shown below:
% jstat -l
JID OWNER COMMAND
--------------- -------------- --------------
0x5eac0000001bd terry -csh
LIMIT NAME USAGE HIGH USAGE CURRENT LIMIT MAX LIMIT
--------------- -------------- -------------- -------------- --------------
cputime 1:05 1:05 unlimited unlimited
datasize 400k 400k unlimited unlimited
files 10 35 400 5000
vmemory 44 201 unlimited unlimited
ressetsize 340 357 unlimited unlimited
processes 2 4 1024 1024 |
If the -l and -P options are specified, the jstat command will print out the same information that the -l option displays with the exception that memory values are shown in pages. SGI systems support multiple page sizes. For more information on pages sizes, see the "Multiple Page Sizes" section, chapter 10, "System Performance Tuning" in the IRIX Admin: System Configuration and Operation manual.
Summary information is always printed. For an explanation of the limit values, see Table 2-1.
For additional information, see the jstat(1) man page.
The ps -j command prints out the process ID, process group ID, session ID, and job ID in hexadecimal:
% ps -j
PID PGID SID JID TTY TIME CMD
253430 253430 253430 0x5eac001bd ttyq12 0:00 csh
254563 254563 253430 0x5eac001bd ttyq12 0:00 ps |
For additional information, see the ps(1) man page.
The array services daemon, arrayd(1M), propagates the job ID from the originating machine to any other machines when starting new processes for the job on other machines in a cluster.
For additional information, see the arrayd(1M) man page.
The cpr(1) command allows you to include job information in the system restart statefile. A JID checkpoint type has been added to the cpr -p option. This JID type allows you to checkpoint and restart an entire job. See the example as follows:
% cpr -c ckpt02 -p 0x8000000000001234:JID |
This example checkpoints all the processes contained within a job with the job ID 0x8000000000001234 to the statefile directory ./ckpt02.
For additional information, see the cpr(1) man page.
If you have job limits software installed on your system and want jobs started via the remote shell server (rshd(1M)) and remote execution server (rexecd(1M)) to recognize the SIGXCPU signal, you must update the /etc/default/rshd and /etc/default/rexecd files, respectively. You must set the SVR4_SIGNALS parameter to NO. This allows the rshd and rexecd servers to recognize the SIGXCPU signal.
For additional information, see the rsh(1M) and rexecd(1M) man pages.
Message Passing Interface (MPI) jobs requires a great number of file descriptors. By default, a job's current limit for the files limit is set to 400 as shown by the jstat command with the -l option:
% jstat -l
JID OWNER COMMAND
------------------ -------------- --------------
0x23fc000000000035 user -csh
LIMIT NAME USAGE HIGH USAGE CURRENT LIMIT MAX LIMIT
------------------ -------------- -------------- -------------- --------------
cputime 0 0 unlimited unlimited
datasize 80k 208k unlimited unlimited
files 8 28 400 5000
vmemory 2384k 9824k unlimited unlimited
ressetsize 608k 2320k unlimited unlimited
threads 1 1 2048 2048
processes 2 6 1024 1024
physmem 608k 2320k unlimited unlimited |
If you run MPI jobs on systems with 16 or more CPUs, the default current limit for files set at 400 is easily encountered and an error message similar to the following is issued:
MPI jobs fail with the error MPI: fork_slaves/fork: Resource temporarily unavailable MPI: daemon terminated: mice1 - job aborting |
To avoid this error, set the default current limit for the files limit higher when you are running MPI jobs. For information on setting system job limits, see “User Limits Database” and “Using systune to Display and Set Job Limits”.
The following table contains the recommended default current limit for the files limit when you are running large MPI jobs depending upon the number of CPUs in your system. The recommended settings are approximate values.
| Number of CPUs | Default Current Limit or Higher | |
| 16 | 351 | |
| 17 | 380 | |
| 18 | 410 | |
| 20 | 472 | |
| 25 | 648 | |
| 30 | 848 | |
| 50 | 4448 |
Use the inst(1M) software installation tool or the swmgr(1M) software management tool to install kernel job limits software. For more information on inst(1M) and swmgr(1M), see IRIX Admin: Software Installation and Licensing in the IRIX Admin manual set and their respective man pages.
To install the kernel job limits software on IRIX systems, install this subsystem: eoe.sw.jlimits.
Once the job limits software is installed, run the autoconfig(1M) command and reboot the system.
To turn off job limits, you must deinstall the eoe.sw.jlimits software module and then reboot the system.
If you are updating entries in the ULDB and they do not change the job limit values on your system, make sure that limit names used in the ULDB and limit names used in the systune joblimits group are exactly the same. The ULDB cannot determine which job limit variables are valid and which are not. If the symbolic names in the ULDB are entered incorrectly, values from the systune joblimits group will be applied. For information on limit names, see Table 2-1.
The man command provides online help on all resource management commands. To view a man page online, type mancommandname.
The following user-level man pages are provided with job limits software:
| User-level man page | Description |
| jlimit(1) | Displays and sets resource limits |
| jstat(1) | Displays job status information |
| showlimits(1) | Displays limits information from the user limits database |
The following administrator man page is provided with job limits software:
| Administrator man page | Description |
| genlimits(1M) | Creates the user limits data base |
The following online man pages are provided with job limits software to help those who develop applications that use job limits software:
| Application interface man page | Description |
| getjid(2) | Get job ID |
| getjlimit(2) | Control a job's maximum system resource consumption |
| getjusage(2) | Get job usage information |
| killjob(2) | Terminates all processes for the specified job |
| jlimit_startjob(3c) | Creates a new job |
| makenewjob(2) | Creates a new job container |
| setjusage(2) | Updates the resource usage values for the specified job ID. |
| setwaitjobpid(2) | Sets a job to wait for a specified process ID (PID) to call the waitjob(2) function |
| waitjob(2) | Obtains information about a terminated job |
| uldb_get_limit_values(3c) | Collection of functions that all interact with the user limits database (ULDB) to retrieve or set limit values for a domain or user. |
The following job limits related error messages are returned:
| EBUSY | The requested job ID value is in use. | |
| EINVAL | Invalid parameters encountered. | |
| ENOATTR | The domain name or namelist are not specified. | |
| ENOEXIST | The jlimits file does not exit. | |
| ENOJOB | A job with the specified job ID cannot be found. | |
| ENOMEM | Sufficient memory is not available. | |
| ENOPKG | The job limits software is not installed. |