There are several kinds of executable and nonexecutable program units in Fortran. Each of these program units provides unique functionality. The executable program units are the main program and procedure subprograms. The nonexecutable program units are block data units and modules, which provide definitions used by other program units. This chapter describes each of these units as well as the closely related concepts of host association and use association.
A Fortran program is a collection of program units. One and only one of these units must be a main program. In all but the simplest programs, the individual tasks are typically organized into a collection of function and subroutine subprograms and module program units. The program can be organized so that the main program drives (or manages) the collection of program units making up the executable program, but other program organizations can work as well.
Each program unit is an ordered set of constructs and statements. The heading statement identifies the kind of program unit it is, such as a subroutine or a module; it is optional in a main program. An ending statement marks the end of the unit. The principal kinds of program units are as follows:
The module program unit can help you to organize elements of a program. A module itself is not executable, but it can contain data declarations, derived-type definitions, procedure interface information, and subprogram definitions used by other program units. Block data program units are also nonexecutable and are used only to specify initial values for variables in named common blocks.
Program execution begins with the first executable statement in the main program. The MIPSpro Fortran Language Reference Manual, Volume 1, explains the high-level syntax of Fortran and how to put a Fortran program together. It is a good place to review the ways statements can be combined to form a program unit.
The Fortran program in Figure 3-1 is an example of a program that contains four program units: a main program, a module, and two subroutines.
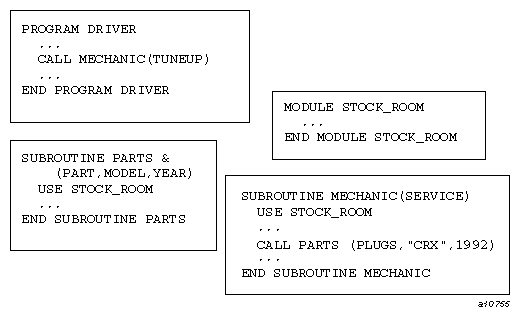
Module STOCK_ROOM contains data and procedure information used by subroutines MECHANIC and PARTS. The main program DRIVER invokes the task represented by subroutine MECHANIC, but DRIVER does not itself need the information in STOCK_ROOM.
The main program specifies the overall logic of a Fortran program and is where execution of the program begins. A main program is similar to the other program units, particularly external subprograms, and has the following principal parts:
The specification part, which defines the data environment of the program
The execution part, in which execution begins and program logic is described
The internal procedure part, which is included if the main program contains internal procedures
The principal ways of stopping the execution are as follows:
Executing a STOP statement anywhere in the program (in any program unit in the program)
Reaching the end of the main program
Encountering certain error conditions
A main program is defined as follows:
| main_program | is |
| |
| program_stmt | is |
| |
EXT | arg | is |
| |
| end_program_stmt | is |
|
| Note: The Fortran standard does not specify the use of a parenthesized list of args at the end of a PROGRAM statement. |
The preceding BNF definition results in the following general format to use for constructing a main program:
[ PROGRAM program_name ] [ specification_part ] [ execution_part ] [ internal_subprogram_part ] END [ PROGRAM [ program_name ] ] |
The simplest of all programs is as follows:
END |
The following simple program is more interesting:
PROGRAM SIMPLE PRINT *, 'Hello, world.' END PROGRAM SIMPLE |
The PROGRAM statement is optional for a main program.
The program name on the END statement, if present, must be the same as the name on the PROGRAM statement and must be preceded by the keyword PROGRAM.
A main program has no provisions for dummy arguments.
A main program must not be referenced anywhere; that is, a main program must not be recursive (either directly or indirectly).
A main program must not contain RETURN or ENTRY statements, but internal procedures in a main program can have RETURN statements.
The principal purpose of the specification part is to describe the nature of the data environment of the program: the arrays, types and attributes of variables, initial values, and so forth. The complete list of specification part statements is given in the MIPSpro Fortran Language Reference Manual, Volume 1.
The following list summarizes the Fortran specification statements that are valid in a main program:
ALLOCATABLE
AUTOMATIC
COMMON
DATA
DIMENSION
EQUIVALENCE
EXTERNAL
FORMAT
IMPLICIT
INTRINSIC
NAMELIST
PARAMETER
POINTER
SAVE
TARGET
USE
Derived-type definitions and declarations
Interface blocks
Statement function statement
Type declaration statement
| Note: The POINTER attribute and statement specify dynamic objects. The Cray pointer is an extension to Fortran and is different from the Fortran pointer. They both use the POINTER keyword, but they are specified such that the compiler can differentiate them. The TARGET attribute and statement specify a target for a Fortran pointer. |
In the entity-oriented style of declaration, all attributes of an entity can be declared in the same statement.
OPTIONAL and INTENT attributes or statements cannot appear in the specification part of a main program; they are applicable only to dummy arguments.
The accessibility attributes or statements, PUBLIC and PRIVATE, cannot appear in a main program; they are applicable only within modules.
Automatic objects are not permitted in main programs.
The SAVE attribute or statement can appear in a program, but it has no effect in a main program.
The MIPSpro Fortran Language Reference Manual, Volume 1 lists the execution part statements that can appear in a main program.
The following list summarizes the execution part statements:
ALLOCATE and DEALLOCATE
Assignment statement
Pointer assignment statement
BACKSPACE
BUFFER IN and BUFFER OUT
CALL
CASE construct
CLOSE
CONTINUE
CYCLE
DATA
DO construct
END
ENDFILE
ENTRY
EXIT
FORALL statement and construct
FORMAT
Computed GO TO
GO TO
Arithmetic IF
IF statement
IF construct
INQUIRE
NULLIFY
OPEN
PRINT
READ
REWIND
STOP
WHERE statement and WHERE construct
WRITE
| Note: Pointer assignment statement should not be confused
with Cray pointers and Cray character pointers. The Fortran standard does
not describe Cray pointers or Cray character pointers.
The Fortran standard does not describe BUFFER IN and BUFFER OUT statements. The Fortran standard has declared the arithmetic IF and computed GO TO statements to be obsolescent. |
Internal procedures are very much like external procedures, except that they are packaged inside a main program or other procedure subprograms. This makes their names local, rather than global like external procedures, so an internal procedure can be referenced only within the program unit that contains its definition.
The format of the internal procedure part of the host is as follows:
CONTAINS internal_subprogram [ internal_subprogram ] ... |
Each internal procedure is either a function or subroutine, as follows:
function_statement [ specification_part ] [ execution_part ] END FUNCTION [ function_name ] |
subroutine_statement [ specification_part ] [ execution_part ] END SUBROUTINE [ subroutine_name ] |
The following is an example of an internal procedure:
PROGRAM WEATHER
. . .
CONTAINS
FUNCTION STORM(CLOUD)
. . .
END FUNCTION STORM
END |
Internal procedures must not themselves contain internal procedures; that is, internal procedures must not be nested.
Internal procedures must not contain ENTRY statements.
Internal procedures must not contain PUBLIC or PRIVATE attributes or statements.
Internal procedures must not be passed as actual arguments.
The specification part of an internal procedure may contain the same statements as the specification part of a main program, plus the INTENT statement and the OPTIONAL statement.
The execution part of an internal procedure may contain the same statements as the execution part of a main program, plus the RETURN statement.
There must be at least one internal subprogram after the CONTAINS statement.
An internal procedure can be referenced in the execution part of its host (for example, the main program that contains it) and in the execution part of any internal procedure contained in the same host. This includes itself, so internal procedures may be referenced recursively, either directly or indirectly.
An internal procedure name is a local name in its host and therefore is subject to the rules governing such names. An internal procedure name has the following characteristics:
It gives the internal procedure precedence over any external procedure or intrinsic procedure with the same name
It must be different from the names of other internal procedures in the same host and different from the imported names of any module procedures either imported into the host or into the internal procedure itself
It must be different from any other local name in the host or itself and from names made accessible by a USE statement
The next section describes the rules governing other names that appear in the host and/or the internal procedure. The host association rules apply to a module procedure and its host module, as well as to an internal procedure and its host (such as a main program).
External subprograms are global to the Fortran program; they can be referenced or called anywhere. An internal procedure, on the other hand, is known only within its host.
The major difference between external procedures and internal (and module) procedures is not syntactic; it is the fact that an external procedure interface is not known at the point of procedure reference. Also, internal (and module) procedures are compiled with their hosts, whereas external procedures usually are compiled separately. For internal (and module) procedures, interface information is available at the point of procedure reference. This is a very significant difference and a major practical advantage of internal and module procedures; Section 4.8 in Chapter 4, describes the benefits of explicit interfaces, which come automatically with internal and module procedures, but must be provided for external procedures.
Another difference between internal and external procedures is that external procedures can contain internal procedures; internal procedures cannot.
The organization of external subprograms is very much like that of main programs. As the following formats show, external subprograms are of two types, functions and subroutines:
function_statement [ specification_part ] [ execution_part ] [ internal_subprogram_part ] END [ FUNCTION [ function_name ] ] |
subroutine_statement [ specification_part ] [ execution_part ] [ internal_subprogram_part ] END [ SUBROUTINE [ subroutine_name ] ] |
The following are examples of external procedures:
FUNCTION FOOTBALL(GAME)
INTEGER FOOTBALL
FOOTBALL = N_PLAYERS
. . .
END FUNCTION FOOTBALL
SUBROUTINE SATURDAY(SEVEN)
X = . . .
END |
Unlike the main program, the program unit heading (FUNCTION or SUBROUTINE statement) is required in an external subprogram. For more information on the FUNCTION statement, see Section 4.3.1 in Chapter 4. For more information on the SUBROUTINE statement, see Section 4.2.1 in Chapter 4.
The procedure name, if present on the END statement, must be the same as that in the heading statement.
OPTIONAL and INTENT attributes and statements for dummy arguments are allowed in the specification part of an external subprogram, but only for dummy arguments.
The specification and execution parts of an external subprogram can contain ENTRY statements and the execution part may contain RETURN statements.
External subprograms must not contain PUBLIC or PRIVATE attributes or statements.
External procedures can be directly or indirectly recursive, in which case the RECURSIVE keyword is required on the heading statement.
An external subprogram is the host to any internal procedures defined within it.
An external procedure name can be used as an actual argument in a procedure reference, corresponding to a dummy procedure argument in the procedure referenced.
Procedures, including internal, external, and module procedures, are described in detail in section Chapter 4, “Using Procedures”.
A module allows you to package data specifications and procedures in one place for use in any computational task in the program.
Anything required by more than one program unit can be packaged in modules and made available where needed. A module is not itself executable, though the procedures it contains can be individually referenced in the execution part of other program units. The number of modules is not restricted, and a module may use any number of other modules as long as the access path does not lead back to itself. Modules are powerful tools for managing program organization and simplifying program design.
A module is defined as follows:
| module | is |
| |
| module_stmt | is | MODULE module_name | |
| end_module_stmt | is |
|
The preceding BNF definition results in the following general format to use for constructing a module:
MODULE module_name [ specification_part ] [ module_subprogram_part ] END [ MODULE [ module_name ] ] |
The module name, if present on the END statement, must be the same as on the MODULE statement.
The form of the specification part of a module is similar to that for other program units. The statements it can contain are as follows:
ALLOCATABLE
COMMON
DATA
DIMENSION
EQUIVALENCE
EXTERNAL
IMPLICIT
INTRINSIC
NAMELIST
PARAMETER
POINTER
PRIVATE
PUBLIC
SAVE
TARGET
USE
Derived-type definition statements
Interface blocks
Type declaration statements
The following paragraphs describe the rules and restrictions that apply to the specification part of a module. The specification parts of the module procedures have the same rules as those for external procedures, which are described in the previous section.
The following types of attributes and statements are not allowed: AUTOMATIC attribute, OPTIONAL or INTENT attributes or statements, ENTRY statements, FORMAT statements, automatic objects, and statement function statements.
PUBLIC and PRIVATE attributes and statements are allowed.
The SAVE attribute and statement can be used in the specification part of a module to ensure that module data object values remain intact. Without SAVE, module data objects remain defined as long as any program unit using the module has initiated, but not yet completed, execution. However, when all such program units become inactive, any data objects in the module not having the SAVE attribute become undefined. SAVE can be used to specify that module objects continue to be defined under these conditions.
The following is an example of a simple module for providing global data:
! This module declares three scalar variables (A, ! KA, and X) and two arrays (Y and Z). X is given ! an initial value. These five variables can be ! considered to be global variables that can ! selectively be made available to other program! units. ! MODULE T_DATA INTEGER :: A, KA REAL :: X = 7.14 REAL :: Y(10,10), Z(20,20) END MODULE T_DATA ! ! The USE statement makes A, KA, X, Y, and Z ! available to subroutine TASK_2! SUBROUTINE TASK_2 USE T_DATA . . . END SUBROUTINE TASK_2 |
The module subprogram part is similar to the internal procedure part of a main program or external subprogram. It is a collection of procedures local to the module and sharing its data environment through host association. The two principal differences between module subprograms and internal subprograms are as follows:
The organization, rules, and restrictions of module procedures are those of external procedures rather than internal procedures. For example, module procedures can contain internal procedures.
Module procedures are not strictly local to the host module, nor are they global to the program. Only program units using the module can access the module's procedures not specified to be PRIVATE.
The form of the module subprogram part is as follows:
CONTAINS module_subprogram [ module_subprogram ] ... |
There must be at least one module subprogram after the CONTAINS statement.
Each module subprogram is a function or subroutine and has one of the following formats:
function_statement [ specification_part ] [ execution_part ] [ internal_subprogram_part ] END FUNCTION [function_name ] |
subroutine_statement [ specification_part ] [ execution_part ] [ internal_subprogram_part ] END SUBROUTINE [ subroutine_name ] |
An example of a module procedure is as follows:
MODULE INTERNAL
. . .
CONTAINS
FUNCTION SET_INTERNAL(KEY)
. . .
END FUNCTION
END |
The rules for host association and implicit typing in a module procedure are the same as those described for internal procedures in Section 6.2.1.3 in Chapter 6. A module procedure acquires access to entities in its host module through host association, but not to entities in a program unit that uses the module.
A program unit can use the specifications and definitions in a module by referencing (using) the module. This is accomplished with a USE statement in the program unit requiring access to the specifications and definitions of that module. Such access causes an association between named objects in the module and the using program unit and is called use association . USE statements must immediately follow the program unit heading.
Each entity in a module has the PUBLIC or PRIVATE attribute, which determines the accessibility of that entity in a program unit using the module. A PRIVATE entity is not accessible (that is, it is hidden) from program units using the module. A PUBLIC entity is accessible, although its accessibility may be further limited by the USE statement itself. Figure 3-2 depicts these phenomena:
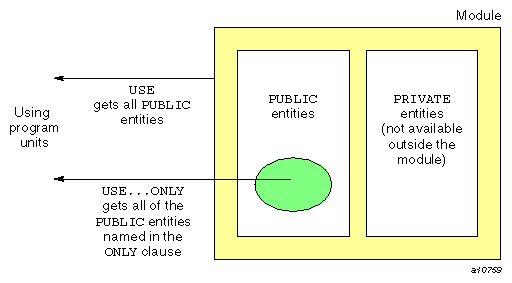
The USE statement gives the program unit access to public entities in the module and is defined as follows:
| use_stmt | is |
| |
or |
| |||
| rename | is |
| |
| only | is |
| |
or |
| |||
or |
| |||
| only_use_name | is |
| |
| only_rename | is |
|
Specifying a USE statement with a rename_list allows any of the public entities in the module to be renamed to avoid name conflicts or to blend with the readability flavor in the using program unit.
Examples:
USE FOURIER USE S_LIB, PRESSURE => X_PRES |
With both USE statements in the preceding example, all public entities in the respective modules are made accessible. In the case of FOURIER, the names are those specified in the module. In the case of S_LIB, the entity named X_PRES is renamed PRESSURE in the program unit using the module. The other entities accessed from S_LIB have the same name in the using program unit as in the module.
To restrict the entities accessed from a module, specify ONLY on the USE statement, as follows:
USE module_name, ONLY: only_list |
In this case, the using program unit has access only to those entities explicitly identified in the ONLY clause of the USE statement. All items in this list must identify public entities in the module. As with the unrestricted form of the USE statement, named accessed entities may be renamed for local purposes. The possible forms of each item in the only_list are as follows:
| [ local_name => ] module_entity_name |
| OPERATOR(defined_operator) |
| ASSIGNMENT(=) |
The local_name, if present, specifies the name of the module entity in the using program unit.
USE MTD, ONLY: X, Y, OPERATOR( .ROTATE. ) USE MONTHS, ONLY: JANUARY => JAN, MAY, JUNE => JUN |
In the case of MTD, only X, Y, and the defined operator .ROTATE. are accessed from the module, with no renaming. In the case of MONTHS, only JAN, MAY, and JUN are accessed. JAN is renamed JANUARY and JUN is renamed JUNE.
In addition, specifying the statement on the left is equivalent to specifying the two statements on the right:
USE MTD, ONLY: X, Y USE MTD, ONLY: X
USE MTD, ONLY: Y |
The following items can be defined, declared, or specified in a module, and may be public. They are accessed through the USE statement by other program units. Any public entity, except a defined operator or assignment interface, can be renamed in the using program unit.
Declared variables
Named constants
Derived-type definitions
Procedure interfaces
Module and intrinsic procedures
Generic identifiers
Namelist groups
Note that the preceding list does not contain the implicit type rules of the module; these are not accessible through a USE statement.
A common block can be declared in a module. Because a common block name is global, however, it is not one of the name categories that is made available to another program unit via a USE statement. The names of the members of the common block in a module, though, are made available through the USE statement; these member names can be given local names through the USE statement renaming clauses. Consider, for example, the following module:
MODULE definer COMMON /def/ i, j, r END MODULE |
All three of the members of common block DEF are made accessible to a program unit containing the following USE statement because all three variables are public entities of the module:
USE definer |
The following USE statement limits access to only common block member R and gives it the local name MY_R:
USE def, ONLY: MY_R => R |
The default accessibility for all entities in a module is PUBLIC unless this default has been changed by a PRIVATE statement with an empty entity list. If the default has been turned to PRIVATE, an entity can be made PUBLIC by its appearance in a PUBLIC statement or in a type declaration that contains the PUBLIC attribute. An entity can be specified to be PRIVATE in a PRIVATE statement or in a type declaration statement that contains the PRIVATE attribute.
Each named entity in a module is classified as either public or private. Regardless of this classification, all module entities can be used freely within the module, including within module procedures in the module; within a module procedure a module entity is governed only by the rules of host association. Outside the module, however, only the public entities are accessible (via the USE statement). Figure 3-3 illustrates these rules:
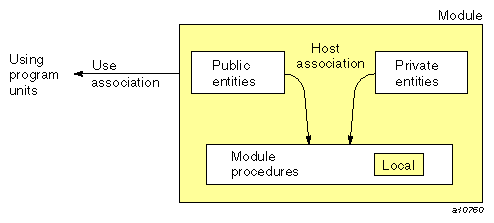
When using modules, name conflicts can occur in the following two ways:
A public entity in a module might have the same name as a local entity in the using program.
Two modules being used might each have a public entity with the same name. Such a name conflict is allowed if and only if that name is never referenced in the using program. If a name is to be referenced in the using program, potential conflicts involving that name must be prevented through use of the rename or ONLY facilities of the USE statement. This is the case even if the using program is another module.
Example:
MODULE BLUE
INTEGER A, B, C, D
END MODULE BLUE
MODULE GREEN
USE BLUE, ONLY : AX => A
REAL B, C
END MODULE GREEN
! in program RED:
! integer A is accessed as AX or A
! integer B is accessed as B
! real B is accessed as BX
! neither C is accessible, because
! there is a name conflict
PROGRAM RED
USE BLUE ! accesses A, B, C, and D
USE GREEN, BX => B ! accesses A as AX, B as
! BX, and C
REAL D ! Illegal; D cannot be
. . . ! redeclared locally.
END |
The USE statement gives a program unit access to other entities not defined or specified locally within the using program. The association between a module entity and a local entity in the using program unit is termed use association. Host association is analogous, but host association applies only to a module and its module procedures and to internal procedures and their hosts. There are many similarities between use association and host association. Their rules, however, are different in the following two ways:
The implicit typing rules of a module have no effect on the environment of a using program unit
Entities accessed through a USE statement must not be respecified locally
The only exception to the second rule is that if the using program unit is another module, then the using module can specify an entity from the used module to be PRIVATE in the using module, rather than maintaining public accessibility. This is perhaps best illustrated with an example. In the following code, program units using module M2, defined as follows, can access X but not Y, even though Y is a public entity of M1:
MODULE M2
USE M1, ONLY: X, Y
PRIVATE Y
. . .
END MODULE M2 |
The prohibition on respecifying entities accessed via use association includes the use of module data objects in locally specified COMMON and EQUIVALENCE specifications.
While a name accessed from a module must not be respecified locally, the same name can be imported from another module under either of the following conditions:
Both accesses are to the same entity. For example, if a program unit uses both M1 and M2 in the preceding example, both give access to the same X. This is allowed.
The accesses are to different entities, but the using program unit makes no reference to that name.
Some Fortran applications may be easier to write and understand when using modules. Modules provide a way of packaging the following types of data:
Global data, previously packaged in common blocks
User-defined operators
Software libraries
Data abstraction
These uses for modules are summarized in the following sections.
A module provides an easy way of making type definitions and data declarations global in a program. Data in a module does not have an implied storage association or an assumption of any form of sequence or any order of appearance, unless it is a sequence structure or in a common block. Global data in a module can be of any type or combination of types, as follows:
MODULE MODELS COMPLEX :: GTX(100, 6) REAL :: X(100) REAL, ALLOCATABLE :: Y(:), Z(:, :) INTEGER CRX, GT, MR2 END MODULE |
There are alternative ways to use the preceding module. The following statement makes all the data (and their attributes) of the module available:
USE MODELS |
The following statement makes only the data named X and Y and their attributes available to the program using the module:
USE MODELS, ONLY: X, Y |
The following statement makes the data object named Z available, but it is renamed to T for that particular application. In addition, it makes the other public entities of the module MODELS available with the same names they have in the module:
USE MODELS, T => Z |
One way of packaging common blocks is by putting them in a module. Consider the following program:
MODULE LATITUDE COMMON . . . COMMON . . . COMMON /BLOCK1/ . . . END MODULE . . . PROGRAM NAVIGATE USE LATITUDE . . . END |
The USE statement in the preceding example makes all of the variables in the common blocks in the module available to the program NAVIGATE. These common blocks can be made available to other program units in the same way.
Unless there is a reason for variables to have their storage association in a particular order, there is no need to include a common block in a module. The data in a module is already global.
A derived type defined in a module is a user-defined type that can be made accessible to other program units. The same type definition can be referenced through a USE statement by more than one program unit. Consider the following code:
MODULE NEW_TYPE
TYPE TAX_PAYER
INTEGER SSN
CHARACTER(20) NAME
END TYPE TAX_PAYER
END MODULE NEW_TYPE |
In the preceding example, the module NEW_TYPE contains the definition of a new type called TAX_PAYER. Procedures using the module NEW_TYPE may declare objects of type TAX_PAYER.
An interface block can declare new operators or give additional meanings to the intrinsic ones, such as +, .EQ., .OR., and //. The assignment symbol = also can be given additional meanings and may be redefined for derived-type intrinsic assignment. (Derived-type assignment is the only instance of an intrinsic operation or assignment that can be redefined.) These extensions require that the OPERATOR or ASSIGNMENT option be on the interface block, the details of which appear in Section 4.8 in Chapter 4.
A simple example of an OPERATOR interface for matrix inversion requires a function and an interface block defining the new operator. In the following example, which normally (but not necessarily) would be in a module, the function INVERSE defines the desired operation, and the operator .INVERSE. can be used in an expression to reference the function:
INTERFACE OPERATOR(.INVERSE.)
FUNCTION INVERSE(MATRIX_1)
TYPE(MATRIX), INTENT(IN) :: MATRIX_1
TYPE(MATRIX) :: INVERSE
END FUNCTION INVERSE
END INTERFACE |
An example of its use might be as follows (assuming + also has been extended to add a real value and a MATRIX):
1.0 + (.INVERSE. A) |
Data type definitions and operations can be packaged together in a module. Program units using this module will have the convenience of a new data type specific to a particular application. The following is a simple example:
MODULE POLAR_COORDINATES
TYPE POLAR
PRIVATE
REAL RHO, THETA
END TYPE POLAR
INTERFACE OPERATOR(*)
MODULE PROCEDURE POLAR_MULT
END INTERFACE
CONTAINS
FUNCTION POLAR_MULT(P1, P2)
TYPE(POLAR),INTENT(IN) :: P1,P2
TYPE(POLAR) :: POLAR_MULT
POLAR_MULT = &
POLAR(P1%RHO * P2%RHO, &
P1%THETA + P2%THETA)
END FUNCTION POLAR_MULT
. . .
END MODULE POLAR_COORDINATES |
In the function POLAR_MULT, the structure constructor POLAR computes a value that represents the result of multiplication of two arguments in polar coordinates. Any program unit using the module POLAR_COORDINATES has access to both the type POLAR and the extended intrinsic operator * for polar multiplication.
A module can contain a collection of interface blocks for related procedures. Argument keywords, as well as optional arguments, can be used to differentiate various applications using these procedures. The following is a simple example:
MODULE ENG_LIBRARY
INTERFACE
FUNCTION FOURIER(X, Y)
. . .
END
SUBROUTINE INPUT(A, B, C, L)
OPTIONAL C
. . .
END SUBROUTINE INPUT
END INTERFACE
END MODULE ENG_LIBRARY |
The following example shows that an input routine can be called using optional or keyword arguments:
CALL INPUT (AXX, L = LXX, B = BXX) |
A collection of related procedures that need to access the same type definitions and data declarations can be placed in a module. The following example shows this:
MODULE BOOKKEEPING
TYPE, PRIVATE :: ID_DATA
INTEGER ID_NUMBER
CHARACTER(20) NAME, ADDRESS(3)
REAL BALANCE_OR_SALARY
END TYPE ID_DATA
REAL, PRIVATE :: GROSS_INCOME, EXPENSES, &
PROFIT, LOSS
INTEGER, PARAMETER :: NUM_CUST = 1000, &
NUM_SUPP = 100, &
NUM_EMP = 10
CONTAINS
SUBROUTINE ACCTS_RECEIVABLE(CUST_ID, AMOUNT)
. . .
END SUBROUTINE ACCTS_RECEIVABLE
SUBROUTINE ACCTS_PAYABLE(CUST_ID, AMOUNT)
. . .
END SUBROUTINE ACCTS_PAYABLE
SUBROUTINE PAYROLL(EMP_ID, AMOUNT)
. . .
END SUBROUTINE PAYROLL
FUNCTION BOTTOM_LINE(AMOUNT)
. . .
END FUNCTION BOTTOM_LINE
END MODULE |
Independent compilation is the practice of compiling or processing subprograms separately and then using the compiled program units in a number of applications without the inconvenience or cost of recompiling those units.
The Fortran INCLUDE facility behaves as if the source text from another file were inserted in place of the INCLUDE line prior to compilation. This departs from pure independent compilation in some respects because the program unit in which the INCLUDE line is contained now depends on material from elsewhere.
The use of a module is also a departure from pure independent compilation in that a program unit being compiled depends on information from a module.
If the program unit contains a reference to a module, the module must have been previously compiled and available to the using program unit; either through a module search path or appearing previously in the file being compiled. However, if no modules or INCLUDE lines are used, program unit compilation is completely independent of other sources of information.
Because a module is a complete program unit, it can be compiled independently. An advantage is that the module contents can be put into a precompiled form that can be incorporated efficiently during the program units' compilation.
Although there are frequently some dependencies using modules, it is often possible to put together a self-contained package consisting of certain modules and the program units that use them. This package is independent of other packages that might be part of the Fortran program; packages may be used in the same way as independent compilation has been used in the past. For example, such a module package may be compiled independently of the main program and external procedures, both of which may be compiled independently of the module package as long as these external procedures do not use the module package. In cases where program units use the module package, such program units are required to be compiled after the module package is compiled.
A block data program unit initializes data values in a named common block. The block data program unit contains data specifications and initial data values. Executable statements are not allowed in a block data program unit and the block data program unit is referenced only in EXTERNAL statements in other program units; its only purpose is to initialize data.
The block data program unit is defined as follows:
| block_data | is |
| |
| block_data_stmt | is |
| |
| end_block_data_stmt | is |
|
The preceding BNF definition results in the following general format to use for constructing a block data program unit:
BLOCK DATA [ block_data_name ] [ specification_part ] END [ BLOCK DATA [ block_data_name ] ] |
The following is an example of a block data program unit:
BLOCK DATA SUMMER COMMON /BLOCK_2/ X, Y DATA X /1.0/, Y /0.0/ END BLOCK DATA SUMMER |
The name SUMMER appears on the BLOCK DATA statement and the END statement. X and Y are initialized in a DATA statement; both variables are in named common block BLOCK_2.
The compiler allows you to include 26 unnamed block data program units.
| Note: The Fortran standard specifies that there can be at most one unnamed block data program unit in an executable program. |
The block data name on the END statement, if present, must be the same as on the BLOCK DATA statement.
The specification_part can contain any of the following statements or attributes. Other statements are prohibited.
COMMON
DATA
DIMENSION
EQUIVALENCE
IMPLICIT
INTRINSIC
PARAMETER
POINTER
SAVE
TARGET
USE
Derived-type definition
Type declaration
A USE statement in a block data program unit can give access to a limited set of objects, such as named constants, sequence derived types, and variables used only as arguments of inquiry functions. Most uses are disallowed by the restrictions on variables in block data programs.
The block data program unit can initialize more than one named common block.
It is not necessary to initialize an entire named common block.
The compiler permits named common blocks to appear in more than one block data program unit.
| Note: The Fortran standard permits a given named common block to appear in only one block data program unit. |