This chapter provides information about the MIPSpro compiler system and describes the object file format and dynamic linking. Specifically, this chapter covers the topics listed below:
“Selecting Compilation Modes”, explains how to specify n32, 64, or o32 compilation mode and how to set up a compiler.defaults file.
“Object File Format and Dynamic Linking”, discusses object files, including executable and linking format, dynamic shared objects, and position-independent code.
“Source File Considerations”, explains source file naming conventions and the procedure for including header files.
“Compiler Drivers”, lists and explains general compiler-driver options.
“Linking”, explains how to link programs manually (using ld or a compiler) and how to compile multilanguage programs. It also covers Dynamic Shared Objects (DSOs) and how to link them into a program.
“Getting Information About Object Files”, provides information on how to use the object file tools to analyze object files.
“Using the Archiver to Create Libraries”, explains how to use the archiver, ar.
“Debugging”, describes the compiler-driver options for debugging.
For further information on DSOs, see Chapter 3, “Using Dynamic Shared Objects”. For information on optimizing your program, see Chapter 4, “Optimizing Program Performance”.
You can select compilation modes by explicitly specifying them on a compiler command line, defining an environment variable, or specifying a file that defines some of the defaults. This section covers the following topics:
Using a Defaults Specification File
Setting an Environment Variable
When to use -n32 or -64
You can set the following options without explicitly specifying them every time you invoke a compiler.
The Application Binary Interface (ABI)
The instruction set architecture (ISA)
The processor type
The optimization level
The IEEE arithmetic level
Just set the environment variable COMPILER_DEFAULTS_PATH to a colon-separated list of paths designating where the compiler is to look for the compiler.defaults file. If no compiler.defaults file is found, or if the environment variable is not set, the compiler looks in /etc/compiler.defaults . If this file is not found, the compiler resorts to the built-in defaults.
The compiler.defaults file contains a -DEFAULT: option group specifier that specifies the default ABI, ISA, and processor. The compiler issues a warning if you specify anything other than -DEFAULT: option in the compiler.defaults file.
The format of the -DEFAULT: option group is specified in each of the language manuals.
Use the -show_defaults option to print the compiler.defaults being used (if any) and their values. This option is for diagnostic purposes and does not compile any code.
Explicit command-line options override all compiler default settings, and the SGI_ABI environment variable overrides the ABI setting in the compiler.defaults file. The following command overrides a compiler.defaults file that sets -DEFAULT:abi=n32:isa=mips4:proc=r10k and compiles -64 -mips4 -r10000:
% cc -64 foo.c |
The following command overrides the compiler.defaults file and sets the ABI to -o32 and the ISA to -mips2. The -o32 ABI supports only -mips2 (the default) and -mips1 compilations.
% cc -o32 foo.c |
The processor type is ignored by -o32 compilations. Refer to the release notes and man pages for your compiler for information about default settings. Refer to the man pages for your command-line options.
You can set an environment variable (shown in Table 2-1) to specify the compilation mode to use.
Table 2-1. Compilation Mode Environment Variable Specifications
Environment Variable | Description |
|---|---|
setenv SGI_ABI -n32 | Sets the environment for new 32-bit compilation. |
setenv SGI_ABI -64 | Sets the environment for 64-bit compilation. |
setenv SGI_ABI -o32 | Sets the environment for old 32-bit compilation. |
How do you know when to use -n32 or -64 to compile your code? Compile -n32 when you want:
To generate smaller executables than -64.
Executables to have fewer data cache misses and less memory paging than -64.
To access 64 bits: long long and INTEGER*8 are 64-bits long.
Compile -64 if your program:
Requires more than 2 gigabytes of address space.
Will overflow a 32-bit long integer.
This section describes how the compiler system:
The compiler system produces ELF object files. ELF is the format specified by the System V Release 4 Applications Binary Interface (the SVR4 ABI). ELF provides support for DSOs, described in the following section.
Types of ELF object files are as follows:
Relocatable files, which contain code and data in a format suitable for linking with other object files to make a shared object or executable.
DSOs, which contain code and data suitable for dynamic linking. Relocatable files may be linked with DSOs to create a dynamic executable. At run time, the run-time linker combines the executable and DSOs to produce a process image.
Executable files ready for execution. They may or may not be dynamically linked.
You can use this version of the compiler system to construct ABI-compliant executables that run on any operating system supporting the MIPS ABI. Be careful to avoid referencing symbols that are not defined as part of the MIPS ABI specification. For more information, see the following publications:
System V Applications Binary Interface--Revised First Edition. Prentice Hall, ISBN 0-13-880410-9
System V Application Binary Interface MIPS Processor Supplement. Prentice Hall, ISBN 0-13-880170-3.
IRIX uses shared objects called Dynamic Shared Objects, or DSOs. The object code of a DSO is position-independent code (PIC), which can be mapped into the virtual address space of several different processes at once. DSOs are loaded at run time instead of at linking time by the run-time loader, rld . As is true of static shared libraries, the code for DSOs is not included in executable files; thus, executables built with DSOs are smaller than those built with non-shared libraries, and multiple programs may use the same DSO at the same time. For more information on DSOs, see Chapter 3, “Using Dynamic Shared Objects”.
Dynamic linking requires that all object code used in the executable be position-independent code (PIC). For source files in high-level languages, you just need to recompile to produce PIC. Assembly language files must be modified to produce PIC; see the MIPSpro Assembly Language Programmer's Guide for details.
Position-independent code satisfies references indirectly by using a global offset table (GOT), which allows code to be relocated simply by updating the GOT. Each executable and each DSO has its own GOT. For more information on DSOs, see Chapter 3, “Using Dynamic Shared Objects”.
The compiler system produces PIC by default when compiling higher-level language files. All of the standard libraries are provided as DSOs and therefore contain PIC code; if you compile a program into non-PIC, you will be unable to use those DSOs. One of the few reasons to compile non-PIC is to build a device driver, which does not rely on standard libraries.
This section describes conventions for naming source files and including header files.
Each compiler driver recognizes the type of an input file by the suffix assigned to the file name. Table 2-2 describes the possible file name suffixes.
Table 2-2. Driver Input File Suffixes
Suffix | Description |
|---|---|
.s | Assembly source |
.i | Preprocessed source code in the language of the processing driver |
.c | C source |
.C, .c++, .CC, .cc, .CPP, .cpp, .CXX, .cxx | C++ source |
.f.F .for.FOR .f.f90.F90 | FORTRAN 77 source Fortran 90 source |
.p | Pascal source |
.o | Object file |
.a | Object library archive |
.so | DSO library |
The following example compiles preprocessed source code:
f77 -c tickle.i |
The f77 compiler also assumes the file has already been preprocessed (because the suffix is .i) and therefore does not invoke the preprocessor.
Header files, also called include files, contain code that is inserted into the program.
C header files contain information about the libraries with which they are associated. They define such things as data types, data structures, symbolic constants, and prototypes for functions exported by the library. To use those definitions without having to type them into each of your source files, you can use the #include directive to tell the macro preprocessor to include the complete text of the given header file in the current source file. When you include header files in your source files, you can specify definitions conveniently and consistently in each source file that uses any of the library routines.
Fortran include files are specified by the INCLUDE line, which names a file containing source text. That source text is substituted for the INCLUDE line during compilation. The source text can be any Fortran code that is valid in the context of its location in the program.
By convention, C header file names have a .h suffix. Each programming language handles these files the same way, via the macro preprocessor. For example, the stdio.h header file describes, among other things, the data types of the parameters required by the C language printf() function.
For detailed information about standard header files and libraries, see the International Standard ISO/IEC, Programming languages--C, 9899, 1990. Also see “Using Typedefs ” in Chapter 6, for information about the inttypes.h header file.
The #include directive in C and C++ or the INCLUDE line in Fortran tells the preprocessor to replace the directive or line with the text of the indicated header file. The usual way to specify a header file in C is with the following line:
#include <filename> |
The filename is the name of the header file to be included. The angle brackets (< >) surrounding the filename tell the macro preprocessor to search for the specified file only in directories specified by command-line options and in the default header file directory (/usr/include and /usr/include/CC for C++).
In another specification format, filename is given between double quotation marks (“ ”). In this case, the macro preprocessor searches for the specified header file in the current directory first (that is, the directory containing the main program file). If the preprocessor does not find the requested file, it searches the other directories as in the angle-bracket specification.
In Fortran, included text is specified as follows:
INCLUDE 'filename' |
In an f90(1) program, the directory containing filename can be specified on the command line with the -I option. In an f77(1) program, filename must be in the current directory.
A single header file can contain definitions for multiple languages; this setup allows you to use the same header file for all programs that use a given library, no matter what language those programs are in.
To set up a shareable header file, create a .h file and enter the definitions for the various languages as follows:
#ifdef _LANGUAGE_C C Definitions #endif #ifdef _LANGUAGE_C_PLUS_PLUS C++ definitions #endif #ifdef _LANGUAGE_FORTRAN Fortran definitions #endif |
| Note: You must specify _LANGUAGE_ before the language name. To indicate C++ definitions, you must use _LANGUAGE_C_PLUS_PLUS , not _LANGUAGE_C++. |
You can specify language definitions in any order.
This section describes the precompiled header mechanism that is available with the n32 and 64-bit C and C++ compilers. This mechanism is also available for C++ (but not C) in o32-bit mode.
This section contains the following topics:
About precompiled headers, see the following section.
Automatic precompiled header processing, see “Automatic Precompiled Header Processing”.
Other ways to control precompiled headers, see “Other Ways to Control Precompiled Headers”.
PCH performance issues, see “PCH Performance Issues”.
The precompiled header (PCH) file mechanism is available through the C and C++ compilers front ends: fec and fecc. Use PCH to avoid recompiling a set of header files. This is particularly useful when your header files introduce many lines of code, and the primary source files that included them are relatively small.
In effect, fec and fecc take a snapshot of the state of the compilation at a particular point and write it to a file before completing the compilation. When you recompile the same source file or another file with the same set of header files, the PCH mechanism recognizes the snapshot point, verifies that the corresponding PCH file is usable, and reads it back in.
The PCH mechanism can give you a dramatic improvement in compile-time performance. The trade-off is that PCH files may take a lot of disk space.
This section covers the following topics:
PCH file requirements
Reusing PCH files
Obsolete file deletion mechanism
You can enable precompiled header processing by using the -pch option (-Wf, -pch in 32-bit mode) on the command line. With the PCH mechanism enabled, fec or fecc searches for a qualifying PCH file to read in or creates one for use on a subsequent compilation.
The PCH file contains a snapshot of all the code preceding the header stop point. The header stop point is typically the first token in the primary source file that does not belong to a preprocessing directive. The header stop point can also be specified directly by inserting a #pragma hdrstop. For example, consider the following C++ code:
#include “xxx.h” #include “yyy.h” int i; |
In this case, the header stop point is int i (the first non-preprocessor token), and the PCH file will contain a snapshot reflecting the inclusion of xxx.h and yyy.h. If the first non-preprocessor token or the #pragma hdrstop appears within a #if block, the header stop point is the outermost enclosing #if. For example, consider the following C++ code:
#include “xxx.h” #ifndef YYY_H #define YYY_H 1 #include “yyy.h” #endif #if TEST int i; #endif |
In this case, the first token that does not belong to a preprocessing directive is again int i, but the header stop point is the start of the #if block containing the int . The PCH file reflects the inclusion of xxx.h and conditionally the definition of YYY_H and inclusion of yyy.h. The file does not contain the state produced by #if TEST.
PCH File Requirements
A PCH file is produced only if the header stop point and the code preceding it (generally the header files themselves) meet the following requirements:
The header stop point must appear at file scope; it may not be within an unclosed scope established by a header file. For example, a PCH file is not created in the following case:
// xxx.h class A { // xxx.C #include "xxx.h" int i; };The header stop point cannot be inside a declaration started within a header file, and it cannot be part of a declaration list of a linkage specification. For example, a PCH file is not created in the following case:
// yyy.h static // yyy.C #include "yyy.h" int i;
In this case, the header stop point is int i, but since it is not the start of a new declaration, a PCH file is not created
The header stop point cannot be inside a #if block or a #define started within a header file.
The processing preceding the header stop must not have produced any errors. (Note that warnings and other diagnostics are not reproduced when the PCH file is reused.)
References to predefined macros __DATE__ or __TIME__ cannot be included.
Use of the #line preprocessing directive cannot be included.
#pragma no_pch cannot be included.
Reusing PCH Files
When a precompiled header file is produced, in addition to the snapshot of the compiler state, it contains some information that can be checked to determine under what circumstances it can be reused. This information includes the following:
The compiler version, including the date and time the compiler was built.
The current directory (in other words, the directory in which the compilation is occurring).
The command-line options.
The initial sequence of preprocessing directives from the primary source file, including #include directives.
The date and time of the header files specified in #include directives.
This information comprises the PCH prefix. The prefix information of a given source file can be compared to the prefix information of a PCH file to determine whether or not the latter is applicable to the current compilation.
For example, consider the following C++ code:
// a.C #include "xxx.h" ... // Start of code // b.C #include "xxx.h" ... // Start of code |
When you compiled a.C with the -pch option, the PCH file a.pch is created. When you compile b.C (or recompile a.C), the prefix section of a.pch is read in for comparison with the current source file. If the command line options are identical and xxx.h has not been modified, fec or fecc reads in the rest of a.pch rather than opening xxx.h and processing it line by line. This establishes the state for the rest of the compilation.
It may be that more than one PCH file is applicable to a given compilation. If so, the largest (in other words, the one representing the most preprocessing directives from the primary source file) is used. For instance, consider a primary source file that begins with the following code:
#include "xxx.h" #include "yyy.h" #include "zzz.h" |
If one PCH file exists for xxx.h and a second for xxx.h and yyy.h, the latter will be selected (assuming both are applicable to the current compilation). After the PCH file for the first two headers is read in and the third is compiled, a new PCH file for all three headers may be created.
When a precompiled header file is created, it takes the name of the primary source file, with the suffix replaced by pch. Unless -pch_dir is specified, the PCH file is created in the directory of the primary source file.
When a precompiled header file is created or used, a message similar to the following is issued:
"test.C": creating precompiled header file "test.pch" |
Obsolete File Deletion Mechanism
In automatic mode (when -pch is used), the front end considers a PCH file obsolete and deletes it under the following circumstances:
The file is based on at least one out-of-date header file but is otherwise applicable for the current compilation.
The file has the same base name as the source file being compiled (for example, xxx.pch and xxx.C) but is not applicable for the current compilation (for example, because of different command-line options).
You must manually clean up any other PCH file.
Support for PCH processing is not available when multiple source files are specified in a single compilation. If the command line includes a request for precompiled header processing and specifies more than one primary source file, an error is issued and the compilation is aborted.
You can use the following ways to control and tune how precompiled headers are created and used:
You can insert a #pragma hdrstop in the primary source file at a point prior to the first token that does not belong to a preprocessing directive. Thus you can specify where the set of header files subject to precompilation ends, as in the following:
#include "xxx.h" #include "yyy.h" #pragma hdrstop #include "zzz.h"
In this case, the precompiled header file includes the processing state for xxx.h and yyy.h but not zzz.h. This is useful if you decide that the information added by what follows the #pragma hdrstop does not justify the creation of another PCH file.
You can use a #pragma no_pch to suppress the precompiled header processing for a given source file.
You can use the command-line option -pch_dir directoryname to specify the directory in which to search for and create a PCH file.
The relative overhead incurred in writing out and reading in a precompiled header file is quite small for reasonably large header files.
In general, writing out a precompiled header file does not cost much, even if it does not end up being used, and, if it is used, it almost always produces a significant speedup in compilation. The problem is that the precompiled header files can be quite large (from a minimum of about 250 Kbytes to several Mbytes or more), and so you probably do not want many of them sitting around.
You can see that, despite the faster recompilations, precompiled header processing is not likely to be justified for an arbitrary set of files with nonuniform initial sequences of preprocessing directives. The greatest benefit occurs when a number of source files can share the same PCH file. The more sharing, the less disk space is consumed. With sharing, the disadvantage of large precompiled header files can be minimized without giving up the advantage of a significant speedup in compilation times.
To take full advantage of header file precompilation, you should reorder the #include sections of your source files and group the #include directives within a commonly used header file.
The fecc source provides an example of how this can be done. A common idiom is the following:
#include "fe_common.h" #pragma hdrstop #include ... |
In this example, fe_common.h pulls in, directly and indirectly, a few dozen header files. The #pragma hdrstop is inserted to get better sharing with fewer PCH files. The PCH file produced for fe_common.h is slightly over a megabyte in size. Another example, used by the source files involved in declaration processing, is the following:
#include "fe_common.h" #include "decl_hdrs.h" #pragma hdrstop #include ... |
decl_hdrs.h pulls in another dozen header files, and a second, somewhat larger, PCH file is created. In all, the fifty-odd source files of fecc share just six precompiled header files. If disk space is at a premium, you can decide to make fe_common.h pull in all the header files used. In that case, a single PCH file can be used in building fecc.
Different environments and different projects have different needs. You should, however, be aware that making the best use of the precompiled header support will require some experimentation and probably some minor changes to your source code.
The driver commands cc(1), CC(1), f90(1), and f77(1) call subsystems that compile, optimize, assemble, and link your programs. This section describes the default behavior for compiler drivers.
At compilation time, you can select one or more options that affect a variety of program development functions, including debugging, profiling, and optimizing. You can also specify the names assigned to output files. Note that some options have default values that apply if you do not specify them.
When you invoke a compiler driver with source files as arguments, the driver calls other commands that compile your source code into object code. It then optimizes the object code (if requested to do so) and links together the object files, the default libraries, and any other libraries you specify.
Given a source file foo.c, the default name for the object file is foo.o. The default name for an executable file is a.out. The following example compiles source files foo.c and bar.c with the default options:
% cc foo.c bar.c |
This example produces two object files, foo.o and bar.o, and links them with the default C library, libc , to produce an executable called a.out.
| Note: If you compile a single source directly to an executable, the compiler does not create an object file. |
The command-line options for MIPSpro compiler drivers are listed and explained in the man page for your compiler.
The linker, ld, combines one or more object files and libraries (in the order specified) into one executable file, performing relocation, external symbol resolutions, and all other required processing. Unless directed otherwise, the linker names the executable file a.out. See the ld (1) man page for complete information on the linker.
This section summarizes the functions of the linker. It also covers how to link a program manually (without using a compiler driver) and how to compile multilanguage programs. Specifically, this section describes:
Invoking the linker, see the following section.
Usually the compiler invokes the linker as the final step in compilation. If object files produced by previous compilations exist and you want to link them, invoke the linker by using a compiler driver instead of calling ld directly. Just pass the object file names to the compiler driver in place of source file names. If the original source files are in one language, invoke the associated driver and specify the list of object files.
In some cases you may need to invoke ld directly, such as when you are building a shared object or doing special linking not supported by compiler drivers (such as building an embedded system).
For information on the options available to the linker, see the ld man page.
The following command tells the linker to search for the DSO libcurses.so in the directory /usr/lib. If it does not find that DSO, the linker then looks for libcurses.a in /lib. The linker does not look for DSOs in /usr/local/lib, so do not put shared objects there.
% ld foiled.o again.o -lcurses |
If found in any of these places, the DSO or library is linked with the objects foiled.o and again.o; if they are not found, an error is generated.
The assembler driver, as, does not run the linker. To link a program written in assembly language, use one of these procedures:
The linker processes its arguments from left to right as they appear on the command line. Arguments to ld can be object files, DSOs, or libraries. Be sure to list object files before DSOs.
When ld reads a DSO, it adds all the symbols from that DSO to a cumulative symbol table. If it encounters a symbol that is already in the symbol table, it does not change the symbol table entry. If you define the same symbol in more than one DSO, only the first definition is used.
When ld reads an archive, usually denoted by a file name ending in .a, it uses only the object files from that archive that can resolve currently unresolved symbol references. When a symbol is referred to but not defined in any of the object files that have been loaded so far, it is called unresolved.
Once a library has been searched in this way, it is never searched again. Therefore, place libraries after object files on the command line in order to resolve as many references as possible. If a symbol is already in the cumulative symbol table from having been encountered in a DSO, its definition in any subsequent archive or DSO is ignored.
You can specify libraries and DSOs either by explicitly stating a path name or by using the library search rules. To specify a library or DSO by path (either relative to the current directory or absolute), simply include that path on the command line:
% ld myprog.o /usr/lib/libc.so.1 mylib.so |
| Note: libc.so.1 is the name of the standard C DSO, replacing the older libc.a. Similarly, libX11.so.1 is the X11 DSO. Most other DSOs are simply named name.so, without a .1 extension. |
To use the linker's library search rules, specify the library with the -lname option:
% ld myprog.o -lmylib |
When the -lmylib argument is processed, ld searches for a file called libmylib.so. If it cannot find libmylib.so in a given directory, it tries to find libmylib.a there; if it cannot find that either, it moves on to the next directory in its search order.
The default search order uses the path appropriate to the compilation mode:
For -n32, the default search order is /usr/lib32:/lib32.
For -64, the default search order is /usr/lib64:/lib64.
For -o32, the default search order is /usr/lib:/lib.
If ld is invoked from one of the compiler drivers, all -L and -nostdlib options are moved up on the command line so that they appear before any -l name options. For example, consider the command:
% cc file1.o -lm -L mydir |
This command invokes, at the linking stage of compilation, the following:
% ld -L mydir file1.o -lm |
| Note: There are three different kinds of files that contain object code files: non-shared libraries, PIC archives, and DSOs. Non-shared libraries are the old-style library. PIC archives are the default, built using ar from .o files compiled with -KPIC (the default option). They can be linked with other PIC files. DSOs are built from PIC .o files by using ld -shared; see Chapter 3, “Using Dynamic Shared Objects”, for details. |
If the linker tells you that a reference to a certain function is unresolved, check that function's man page to find out which library the function is in. If it is not in one of the standard libraries that ld links in by default, you may need to specify the appropriate library on the command line. For an alternative method of finding out where a function is defined, see “Finding an Unresolved Symbol with ld”.
| Note: Simply including the header file associated with a library routine is not enough; you must also specify the library when linking (unless it is a standard library). No automatic connection exists between header files and libraries. Header files only give prototypes for library routines, not the library code itself. |
This section describes how to link your source files with previously built DSOs; for more information about how to build your own DSOs, see Chapter 3, “Using Dynamic Shared Objects”.
To build an executable that uses a DSO, simply call a compiler driver. For instance, the following command links the resulting object file, needle.o, with the previously built DSO, libthread.so , and the standard C DSO, libc.so.1, if available.
% cc needle.c -lthread |
If no libthread.so exists, but a PIC archive named libthread.a exists, that archive is used with libc.so.1 . So you still get dynamic (run-time) linking. Note that even .a libraries contain position-independent code by default, though it is also possible to build non-shared .a libraries that do not contain PIC.
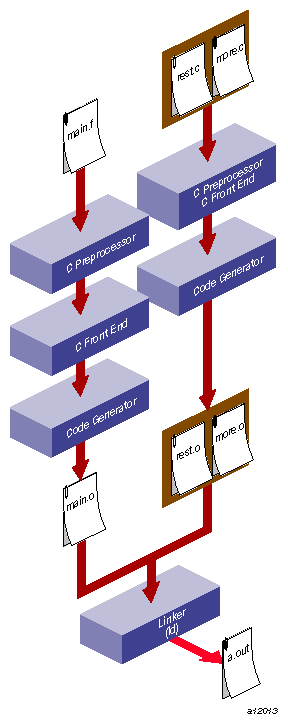
The source language of the main program may differ from that of a subprogram. Follow the steps below to link multilanguage programs. For an illustration of the process, see Figure 2-1.
Compile object files from the source files of each language separately by using the -c option.
For example, if the source consists of a Fortran main program, main.f, and two files of C functions, more.c and rest.c, use the commands:
% cc -c more.c rest.c % f77 -c main.f
These commands produce the object files main.o, more.o, and rest.o.
Use the compiler associated with the language of the main program to link the objects:
% f77 main.o more.o rest.o
The compiler drivers supply the default set of libraries necessary to produce an executable from the source of the associated language. However, when producing executables from source code in several languages, you may need to specify the default libraries explicitly for one or more of the languages. For instructions on specifying libraries, see “Linking Libraries”.
| Note: Use caution when passing pointers and longs between languages, since some languages use different type sizes and structures for data types. |
For specific details about compiling multilanguage programs, see the programming guides for the appropriate languages.
You can use ld to locate unresolved symbols. For example, suppose you are compiling a program, and ld tells you that you are using an unresolved symbol. You may not know where the unresolved symbol is referenced.
To find the unresolved symbol, enter:
% ld -ysymbol file1 ... filen |
You can also enter:
% cc prog.o -Wl,-ysymbol |
The output lists the source file that references symbol .
Several tools provide information on object files and are described in the following sections:
You can trace system call and scheduling activity by using the par command. For more information, see the par(1) man page.
The dis tool disassembles object files into machine instructions. You can disassemble an object, archive library, or executable file.
See the dis(1) man page for descriptions of its options.
The dwarfdump tool provides debugging information from selected parts of DWARF symbolic information in an ELF object file. For more information on DWARF, including option descriptions, see the dwarfdump(1) and dwarf(4) man pages.
The elfdump tool lists headers, tables, and other selected parts of an ELF-format object file or archive file. See the elfdump(1) man page for option descriptions and other information.
The file tool lists the properties of program source, text, object, and other files. This tool attempts to identify the contents of files using various heuristics. It is not exact and often erroneously recognizes command files as C programs. For more information, including option descriptions, see the file(1) man page.
The nm tool lists symbol table information for object files and archive files. To get XPG4 (X/Open Portability Group) format, set the environment variable, _XPG in your environment.
For more information and option descriptions, see the nm(1) man page.
This example demonstrates how to obtain a symbol table listing. Consider the following program, tnm.c:
#include <stdio.h>
#include <math.h>
#define LIMIT 12
int unused_item = 14;
double mydata[LIMIT];
main()
{
int i;
for(i = 0; i < LIMIT; i++) {
mydata[i] = sqrt((double)i);
}
return 0;
} |
Compile the program into an object file by entering:
% cc -c tnm.c |
To obtain symbol table information for the object file tnm.o in BSD format, use the nm -B command:
0000000000 T main 0000000000 B mydata 0000000000 U sqrt 0000000000 D unused_item 0000000000 N _bufendtab |
To obtain symbol table information for the object file tnm.o in SVR4 format, use the nm command without any options:
Symbols from tnm.o: [Index] Value Size Class Type Section Name [0] | 0| |File |ref=4 |Text | tnm.c [1] | 0| |Proc |end=3 int |Text | main [2] | 116| |End |ref=1 |Text | main [3] | 0| |End |ref=0 |Text | tnm.c [4] | 0| |File |ref=6 |Text | /usr/include/math.h [5] | 0| |End |ref=4 |Text | /usr/include/math.h [6] | 0| |Global | |Data | unused_item [7] | 0| |Global | |Bss | mydata [8] | 0| |Proc |ref=1 |Text | main [9] | 0| |Proc | |Undefined| sqrt [10] | 0| |Global | |Undefined| _gp_disp |
The size tool prints information about the sections (such as text, rdata, and sbss) of the specified object or archive files. The elf(4) man page describes the format of these sections, and the size(1) man page describes the options accepted by the size command.
An example of the size command and the listings produced follows:
% size a.out
Section Size Physical Virtual
Address Address
.interp 21 268435856 268435856
.MIPS.options 104 268435880 268435880
.dynamic 464 268435984 268435984
.liblist 20 268436448 268436448
.MIPS.symlib 30 268436468 268436468
.msym 240 268436500 268436500
.dynstr 312 268436744 268436744
.dynsym 720 268437056 268437056
.hash 256 268437776 268437776
.MIPS.stubs 56 268438032 268438032
.text 460 268438088 268438088
.init 24 268438548 268438548
.data 17 268505088 268505088
.sdata 8 268505108 268505108
.got 112 268505120 268505120
.bss 36 268505232 268505232 |
An archive library is a file that includes the contents of one or more object (.o) files. When the linker (ld) searches for a symbol in an archive library, it loads only that object file where that symbol was defined (not the entire library) and links it with the calling program.
The archiver (ar) creates and maintains archive libraries and has these main functions:
Copying new objects into the library
Replacing existing objects in the library
Moving objects around within the library
Extracting individual objects from the library
Creating a symbol table for the linker to search symbols
The following section explains the syntax of the ar command and lists some options and examples of how to use it. See the ar(1) man page for details.
| Note: ar simply strings together whatever object files you tell it to archive. For information about building DSOs and converting libraries to DSOs, see Chapter 3, “Using Dynamic Shared Objects”. |
To create a new library, libtest.a, and add object files to it, enter:
% ar -cq libtest.a mcount.o mon1.o string.o |
The -c option suppresses an archiver message during the creation process. The -q option creates the library and puts mcount.o, mon1.o, and string.o into it.
To replace an object file in an existing library, enter:
% ar -r libtest.a mon1.o |
The -r option replaces mon1.o in the library libtest.a. If mon1.o does not already exist in the library libtest.a, it is added.
| Note: If you specify the same file twice in an argument list of files to be added to an archive, that file appears twice in the archive. |
The compiler system provides the dbx(1) debugging tool, which is described in detail in the dbx User's Guide, and cvd(1), which is part of the ProDev WorkShop suite of performance tools. For information about the WorkShop tools, see the ProDev WorkShop: Overview.
Before using one of the debuggers, specify the -g driver option to produce executables containing information that the debugger can use (see the dbx(1) or cvd man page).