When confronted with a program composed of hundreds of modules and thousands of lines of code, it would require a huge (and inefficient) effort to tune the entire program. Tuning should be concentrated on those few sections of the code where the work will pay off with the biggest gains in performance. These sections of code are identified with the help of the profiling tools.
The hardware counters in the R10000 CPU, together with support from the IRIX kernel, make it possible to record the run-time behavior of a program in many ways without modifying the code. The profiling tools are summarized as follows:
perfex runs a program and reports exact counts of any two selected events from the R10000 hardware event counters. Alternatively, it time-multiplexes all 32 countable events and reports extrapolated totals of each. perfex is useful for identifying what problem (for example, secondary data cache misses) is hurting the performance of your program the most.
Speedshop (actually, the ssrun command) runs your program while sampling the state of the program counter and stack, and writes the sample data to a file for later analysis. You can choose from a wide variety of sampling methods, called “experiments.” Speedshop is useful for locating where in your program the performance problems occur.
prof analyzes a Speedshop data file and displays it in a variety of formats.
dprof, like Speedshop, samples a program while it is executing, and records the program's memory access information as a histogram file. It identifies which data structures in the program are involved in performance problems.
dlook runs a program and at the end, displays the placement of its memory pages to the standard error file.
Use these tools to find out what constrains the program and which parts of it consume the most time. Through the use of a combination of these tools, you can identify most performance problems.
The simplest profiling tool is perfex, documented in the perfex(1) man page. It is conceptually similar to the familiar timex program, in that it runs a subject program and records data about the run:
% perfex options command arguments |
The subject command and its arguments are given. perfex sets up the IRIX kernel interface to the R10000 hardware event counters (for a detailed overview of the counters, see Appendix B, “R10000 Counter Event Types ”), and forks the subject program. When the program ends, perfex writes counter data to standard output. Depending on the options you specify, perfex reports an exact count of one or two countable events (see Table B-1 for a list from which you can choose one number from each column in the table), or it reports an approximate count of all 32 countable event types. perfex gathers the information with no modifications to the subject program, and with only a small effect on its execution time.
Use perfex options to specify one or two events to be counted. When you do this, the counts are absolute and repeatable, but dependent on the amount of other system-wide activity. You can experiment with perfex by applying it to familiar commands, as in Example 4-1.
Example 4-1. Experimenting with perfex
> perfex -e 15 -e 18 date +%w.%V 3.26 Summary for execution of date +%w.%V 15 Graduated instructions...................................... 43334 18 Graduated loads............................................. 9356 |
perfex runs the subject program and reports the exact counts of the requested events. You can use this mode to explore any program's behavior. For example, you could run a program, counting graduated instructions and graduated floating-point instructions (perfex -e 15 -e 21), under a range of input sizes. From the results, you could draw a graph showing how instruction count grows as an exact function of input size.
When you specify option -a (all events), perfex multiplexes all 32 events over the program run. The IRIX kernel rotates the counters each time the dispatching clock ticks (100 HZ). Each event count is active 1/16 of the time during the program run, and then scaled by 16 in the report.
Because they are based on sampling, the resulting counts have some unavoidable statistical error. When the subject program runs in a stable execution mode for a number of seconds, the error is small and the counts are repeatable. When the program runs only a short time, or when it shifts rapidly between radically different regimes of instruction or data use, the counts are less dependable and less repeatable.
Example 4-2 shows the perfex command and output, applied to a CPU-intensive sample program called adi2.f (see Example C-1).
Example 4-2. Output of perfex -a
% perfex -a -x adi2 WARNING: Multiplexing events to project totals--inaccuracy possible. Time: 7.990 seconds Checksum: 5.6160428338E+06 0 Cycles...................................................... 1645481936 1 Issued instructions......................................... 677976352 2 Issued loads................................................ 111412576 3 Issued stores............................................... 45085648 4 Issued store conditionals................................... 0 5 Failed store conditionals................................... 0 6 Decoded branches............................................ 52196528 7 Quadwords written back from scache.......................... 61794304 8 Correctable scache data array ECC errors.................... 0 9 Primary instruction cache misses............................ 8560 10 Secondary instruction cache misses.......................... 304 11 Instruction misprediction from scache way prediction table.. 272 12 External interventions...................................... 6144 13 External invalidations...................................... 10032 14 Virtual coherency conditions................................ 0 15 Graduated instructions...................................... 371427616 16 Cycles...................................................... 1645481936 17 Graduated instructions...................................... 400535904 18 Graduated loads............................................. 90474112 19 Graduated stores............................................ 34776112 20 Graduated store conditionals................................ 0 21 Graduated floating point instructions....................... 28292480 22 Quadwords written back from primary data cache.............. 32386400 23 TLB misses.................................................. 5687456 24 Mispredicted branches....................................... 410064 25 Primary data cache misses................................... 16330160 26 Secondary data cache misses................................. 7708944 27 Data misprediction from scache way prediction table......... 663648 28 External intervention hits in scache........................ 6144 29 External invalidation hits in scache........................ 6864 30 Store/prefetch exclusive to clean block in scache........... 7582256 31 Store/prefetch exclusive to shared block in scache.......... 8144 |
The -x option requests that perfex also gather counts for kernel code that handles exceptions, so the work done by the OS to handle TLB misses is included in these counts.
The raw event counts are interesting, but it is more useful to convert them to elapsed time. Some time estimates are simple; for example, dividing the cycle count by the machine clock rate gives the elapsed run time (1645481936 ÷ 195 MHz = 8.44 seconds). Other events are not as simple and can be stated only in terms of a range of times. For example, the time to handle a primary cache miss varies depending on whether the needed data are in the secondary cache, in memory, or in the cache of another CPU. You can request analysis of this kind using the -y option.
When you use both -a and -y, perfex collects and displays all event counts, but it also displays a report of estimated times based on the counts. Example 4-3 shows, again, the program adi2.f.
Example 4-3. Output of perfex -a -y
% perfex -a -x -y adi2
WARNING: Multiplexing events to project totals--inaccuracy possible.
Time: 7.996 seconds
Checksum: 5.6160428338E+06
Based on 196 MHz IP27
Typical Minimum Maximum
Event Counter Name Counter Value Time (sec) Time (sec) Time (sec)
===================================================================================================================
0 Cycles...................................................... 1639802080 8.366337 8.366337 8.366337
16 Cycles...................................................... 1639802080 8.366337 8.366337 8.366337
26 Secondary data cache misses................................. 7736432 2.920580 1.909429 3.248837
23 TLB misses.................................................. 5693808 1.978017 1.978017 1.978017
7 Quadwords written back from scache.......................... 61712384 1.973562 1.305834 1.973562
25 Primary data cache misses................................... 16368384 0.752445 0.235504 0.752445
22 Quadwords written back from primary data cache.............. 32385280 0.636139 0.518825 0.735278
2 Issued loads................................................ 109918560 0.560809 0.560809 0.560809
18 Graduated loads............................................. 88890736 0.453524 0.453524 0.453524
6 Decoded branches............................................ 52497360 0.267844 0.267844 0.267844
3 Issued stores............................................... 43923616 0.224100 0.224100 0.224100
19 Graduated stores............................................ 33430240 0.170562 0.170562 0.170562
21 Graduated floating point instructions....................... 28371152 0.144751 0.072375 7.527040
30 Store/prefetch exclusive to clean block in scache........... 7545984 0.038500 0.038500 0.038500
24 Mispredicted branches....................................... 417440 0.003024 0.001363 0.011118
9 Primary instruction cache misses............................ 8272 0.000761 0.000238 0.000761
10 Secondary instruction cache misses.......................... 768 0.000290 0.000190 0.000323
31 Store/prefetch exclusive to shared block in scache.......... 15168 0.000077 0.000077 0.000077
1 Issued instructions......................................... 673476960 0.000000 0.000000 3.436107
4 Issued store conditionals................................... 0 0.000000 0.000000 0.000000
5 Failed store conditionals................................... 0 0.000000 0.000000 0.000000
8 Correctable scache data array ECC errors.................... 0 0.000000 0.000000 0.000000
11 Instruction misprediction from scache way prediction table.. 432 0.000000 0.000000 0.000002
12 External interventions...................................... 6288 0.000000 0.000000 0.000000
13 External invalidations...................................... 9360 0.000000 0.000000 0.000000
14 Virtual coherency conditions................................ 0 0.000000 0.000000 0.000000
15 Graduated instructions...................................... 364303776 0.000000 0.000000 1.858693
17 Graduated instructions...................................... 392675440 0.000000 0.000000 2.003446
20 Graduated store conditionals................................ 0 0.000000 0.000000 0.000000
27 Data misprediction from scache way prediction table......... 679120 0.000000 0.000000 0.003465
28 External intervention hits in scache........................ 6288 0.000000 0.000000 0.000000
29 External invalidation hits in scache........................ 5952 0.000000 0.000000 0.000000
Statistics
=========================================================================================
Graduated instructions/cycle................................................ 0.222163
Graduated floating point instructions/cycle................................. 0.017302
Graduated loads & stores/cycle.............................................. 0.074595
Graduated loads & stores/floating point instruction......................... 5.422486
Mispredicted branches/Decoded branches...................................... 0.007952
Graduated loads/Issued loads................................................ 0.808696
Graduated stores/Issued stores.............................................. 0.761099
Data mispredict/Data scache hits............................................ 0.078675
Instruction mispredict/Instruction scache hits.............................. 0.057569
L1 Cache Line Reuse......................................................... 6.473003
L2 Cache Line Reuse......................................................... 1.115754
L1 Data Cache Hit Rate...................................................... 0.866185
L2 Data Cache Hit Rate...................................................... 0.527355
Time accessing memory/Total time............................................ 0.750045
L1--L2 bandwidth used (MB/s, average per process)........................... 124.541093
Memory bandwidth used (MB/s, average per process)........................... 236.383187
MFLOPS (average per process)................................................ 3.391108
|
For each count, the “maximum,” “minimum,” and “typical” time cost estimates are reported. Each is obtained by consulting an internal table that holds the maximum, minimum, and typical costs for each event, and multiplying this cost by the count for the event. Event costs are usually measured in terms of machine cycles, so the cost of an event depends on the clock speed of the CPU, which is also reported in the output.
The “maximum” value in the table corresponds to the worst-case cost of a single occurrence of the event. Sometimes this can be a pessimistic estimate. For example, the maximum cost for graduated floating-point instructions assumes that every floating-point instruction is a double-precision reciprocal square root, which is the most costly R10000 floating-point instruction.
Because of the latency-hiding capabilities of the R10000 CPU, most events can be overlapped with other operations. As a result, the minimum cost of virtually any event could be zero. To avoid simply reporting minimum costs of zero, which would be of no practical use, the minimum time reported corresponds to the best-case cost of a single occurrence of the event. The best-case cost is obtained by running the maximum number of simultaneous occurrences of that event and averaging the cost. For example, two floating-point instructions can complete per cycle, so the best case cost is 0.5 cycles per floating-point instruction.
The typical cost falls somewhere between minimum and maximum and is meant to correspond to the cost you see in average programs.
The report shows the event counts and cost estimates sorted from most costly to least costly, so that the events that are most significant to program run time appear first. This is not a true profile of the program's execution, because the counts are approximate and because the event costs are only estimates. Furthermore, because events do overlap one another, the sum of the estimated times normally exceeds the program's true run time. This report should be used only to identify which events are responsible for significant portions of the program's run time, and to get an estimate of relative costs.
In Example 4-3, the program spends a significant fraction of its time handling secondary cache and TLB misses (together, as much as 3.1 seconds of its 4.4-second run time). Tuning measures focussed on these areas could have a significant effect on performance.
In addition to the event counts and cost estimates, perfex -y also reports a number of statistics derived from the typical costs. Table 4-1 summarizes these statistics.
Table 4-1. Derived Statistics Reported by perfex -y
Statistic Title | Meaning or Use |
|---|---|
Graduated instructions per cycle | When the R10000 is used to best advantage, this exceeds 1.0. When it is below 1.0, the CPU is idling some of the time. |
Graduated floating point instructions per cycle | Relative density of floating-point operations in the program. |
Graduated loads & stores per cycle | Relative density of memory-access in the program. |
Graduated loads & stores per floating point instruction | Helps characterize the program as data processing versus mathematical. |
Mispredicted branches ÷ Decoded branches | Important measure of the effectiveness of branch prediction, and of code quality. |
Graduated loads ÷ Issued loads | When less than 1.0, shows that loads are being reissued because of cache misses. |
Graduated stores ÷ Issued stores | When less than 1.0, shows that stores are being reissued because of cache misses or contention between threads or between CPUs. |
Data mispredictions ÷ Data scache hits | The count of data misprediction from scache way prediction, as a fraction of all secondary data cache misses. |
Instruction mispredictions ÷ Instruction scache hits | The count of instruction misprediction from scache way prediction, as a fraction of all secondary instruction cache misses. |
L1 Cache Line Reuse | The average number of times that a primary data cache line is used after it has been moved into the cache. Calculated as graduated loads plus graduated stores minus primary data cache misses, divided by primary data cache misses. |
L2 Cache Line Reuse | The average number of times that a secondary data cache line is used after it has been moved into the cache. Calculated as primary data cache misses minus secondary data cache misses, divided by secondary data cache misses. |
L1 Data Cache Hit Rate | The fraction of data accesses satisfied from the L1 data cache. Calculated as 1.0 - (L1 data cache misses ÷ (graduated loads + graduated stores)). |
L2 Data Cache Hit Rate | The fraction of data accesses satisfied from the L2 cache. Calculated as 1.0 - (L2 data cache misses ÷ primary data cache misses). |
Time accessing memory ÷ Total time | A key measure of time spent idling, waiting for operands. Calculated as the sum of the typical costs of graduated loads and stores, L1 data cache misses, L2 data cache misses, and TLB misses, all divided by the total run time in cycles. |
L1-L2 bandwidth used (MBps, average per process) | The amount of data moved between the L1 and L2 data caches, divided by the total run time. The amount of data is taken as: L1 data cache misses times L1 cache line size, plus quadwords written back from L1 data cache times the size of a quadword (16 bytes). For parallel programs, the counts are aggregates over all threads, divided by number of threads. Multiply by the number of threads for total program bandwidth. |
Memory bandwidth used (MBps, average per process) | The amount of data moved between L2 cache and main memory, divided by the total run time. The amount of data is taken as: L2 data cache misses times L2 cache line size, plus quadwords written back from L2 cache times the size of a quadword (16 bytes). For parallel programs, the counts are aggregates over all threads, divided by number of threads. Multiply by the number of threads to get the total program bandwidth. |
MFLOPS (average per process) | The ratio of graduated floating-point instructions and total run time. Note that a multiply-add carries out two operations, but counts as only one instruction, so this statistic can be an underestimate. For parallel programs, the counts are aggregates over all threads, divided by number of threads. Multiply by the number of threads to get the total program rate. |
The statistics shown in Table 4-2 are computed only on R12000 and R14000 CPUs:
Table 4-2. Derived statistics computed on R12000 and R14000 CPUs
Statistic Title | Meaning or Uses |
|---|---|
Cache misses in flight per cycle (average) | This is the count of event 4 (Miss Handling Table (MHT) population) divided by cycles. It can range between 0 and 5 and represents the average number of cache misses of any kind that are outstanding per cycle. |
Prefetch miss rate | This is the count of event 17 (prefetch primary data cache misses) divided by the count of event 16 (executed prefetch instructions). A high prefetch miss rate (about 1) is desirable, since prefetch hits are wasting instruction bandwidth. |
The derived statistics shown in the preceding tables give you useful hints about performance problems in your program. For example:
The cache hit-rate statistics tell you how cache friendly your program is. Because a secondary cache miss is much more expensive than a cache hit, the L2 data cache hit rate needs to be close to 1.0 to indicate that the program is not paying a large penalty for the cache misses. Values of 0.95 and above indicate good cache performance. (For Example 4-3, the rate is 0.69, confirming cache problems in this program.)
The memory bandwidth used indicates the load that the program places on the SN0 distributed memory architecture. Memory access passes through the hub chip (see “Understanding Scalable Shared Memory” in Chapter 1), which serves two CPUs and which saturates at aggregate rates of 620 MBps.
Graduated instructions per cycle less than 1.0 indicate the CPU is stalling often for lack of some resource. Look for causes in: the fraction of mispredicted branches, the fraction of time spent accessing memory, and the different cache statistics; and look in the raw data at the proportion of failed store conditionals.
The output of perfex goes to the standard output stream, and you can process it further with any of the normal IRIX utilities. A shell script can capture the output of a perfex run in a variable and display it, or the output can be filtered using any utility. For an example see Example C-7.
It is easy to apply perfex to an unchanged program, but the data comes from the entire run of the program. Often you want to profile only a particular section of the program—to avoid counting setup work, or to avoid profiling the time spent “warming up” the working sets of cache and virtual memory, or to profile one particular phase of the algorithm.
If you are willing to modify the program, you can use the library interface to perfex, documented in the libperfex(3) man page. You insert one library call to initiate counting and another to terminate it and retrieve the counts. You can perform specific counts of only one or two events; there is no dynamic equivalent to perfex -a. The program must then be linked with the libperfex library:
% f77 -o modules... -lperfex |
You can apply perfex to a program that uses the MPI message-passing library (MPI is summarized in “Message-Passing Models MPI and PVM” in Chapter 8). The key to applying a tool like perfex with MPI is to apply mpirun to the tool command. In the following example, mpirun is used to start a program under perfex:
mpirun -np 4 perfex -mp -o afile a.out |
This example starts copies of perfex on four CPUs. Each of them, in turn, invokes the program a.out, and writes its analysis report into the file afile. It is best to use the perfex option -o to write output to a file, because mpirun redirects the standard output and error streams. For a tip on how to collect standard output from perfex, see Example 8-31.
The SpeedShop package supports program profiling. You use profiling to find out exactly where a program spends its time, that is, in precisely which procedures or lines of code. Then you can concentrate your efforts on those areas of code where there is the most to be gained.
The SpeedShop package supports three different methods of profiling:
Sampling: The unmodified subject program is rhythmically interrupted by some time base, and the program counter is recorded in a trace file on each interruption.
Speedshop can use the system timer or any of the R10000/R12000/R14000 counter events as its time base. Different time bases produce different kinds of information about the program's behavior.
Ideal time: A copy of the program binary is modified to put trap instructions at the end of every basic block. During execution, the exact number of uses of each basic block is counted.
An ideal time profile is an exact profile of program behavior. A variety of reports can be printed from the trace of an ideal count run.
Exception trace: Not really a profiling method, this records only floating-point exceptions and their locations.
Either method of profiling, sampling or ideal time, can be applied to multiprocessor runs just as easily as it is applied to single-CPU runs. Each thread of an application maintains its own trace information, and the histograms can be printed individually or merged in any combination and printed as one profile.
SpeedShop has three parts:
ssrun performs “experiments” (sampling runs) and collects data.
You can use the SpeedShop runtime library routines (see the ssapi man page) to insert caliper points into a program to profile specific sections of code or phases of execution.
prof processes trace data and prepares reports.
These programs are documented in the man pages listed under “Related Man Pages”.
Similar to perfex, the ssrun command executes the subject program and collects information about the run. However, where perfex uses the R10000/R12000 event counters to collect data, ssrun interrupts the program at regular intervals. This is a statistical sampling method. The time base is the independent variable and the program state is the dependent variable. The output describes the program's behavior as a function of the time base.
The quality of sampling depends on the time base that sets the sampling interval. The more frequent the interruptions, the better the data collected, and the greater the effect on the run time of the program. The available time bases are listed in Table 4-3.
Table 4-3. SpeedShop Sampling Time Bases
ssrun Option | Time Base | Effect and Use |
|---|---|---|
-usertime | 30ms timer | Coarsest resolution; experiment runs quickly and output file is small; some bugs noted in speedshop(1) . |
-pcsamp[x] -fpcsamp[x] | 10 ms timer 1 ms timer | Moderate resolution; functions that cause cache misses or page faults are emphasized. Suffix x for 32-bit counts. |
-gi_hwc -fgi_hwc | 32771 insts 6553 insts | Fine-grain resolution based on graduated instructions. Emphasizes functions that burn a lot of instructions. |
-cy_hwc -fcy_hwc | 16411 clocks 3779 clocks | Fine-grain resolution based on elapsed cycles. Emphasizes functions with cache misses and mispredicted branches. |
-ic_hwc -fic_hwc | 2053 icache miss 419 icache miss | Granularity depends on program behavior. Emphasizes code that doesn't fit in L1 cache. |
-isc_hwc -fisc_hwc | 131 scache miss 29 scache miss | Granularity depends on program behavior. Emphasizes code that doesn't fit in L2 cache. |
-dc_hwc -fdc_hwc | 2053 dcache miss 419 dcache miss | Granularity depends on program behavior. Emphasizes code that causes L1 cache data misses. |
-dsc_hwc -fdsc_hwc | 131 scache miss 29 scache miss | Granularity depends on program behavior. Emphasizes code that causes L2 cache data misses. |
-tlb_hwc -ftlb_hwc | 257 TLB miss 53 TLB miss | Granularity depends on program behavior. Emphasizes code that causes page faults. |
-gfp_hwc -fgfp_hwc | 32771 fp insts 6553 fp insts | Granularity depends on program behavior. Emphasizes code that performs heavy FP calculation. |
-prof_hwc | user-set | Hardware counter and overflow value from environment variables. |
-fsc_hwc -ffsc_hwc | 2003 fsc miss 401 fsc miss | Granularity depends on program behavior. Emphasizes code that causes failed store-conditional instructions. |
In general, each time base discovers the program PC most often in the code that consumes the most units of that time base, as follows:
The time bases that reflect actual elapsed time (-usertime, -pcsamp, -cy_hwc) find the PC most often in the code where the program spends the most elapsed time. Time may be spent in that code because the code is executed often; but it might be spent there because those instructions are processed slowly owing to cache misses, contention for memory or locks, or failed branch prediction. Use these time bases to get an overview of the program and to find major trouble spots.
The time bases that reflect instruction counts (-gi_hwc, -gfp_hwc) find the PC most often in the code that actually performs the most instructions. Use these to find the code that could benefit most from a more efficient algorithm, without regard to memory access issues.
The time bases that reflect memory access (-dc_hwc, -dsc_hwc, -tlb_hwc) find the PC most often in the code that has to wait for its data to be brought in from another level of the memory hierarchy. Use these to find memory access problems.
The time bases that reflect code access (-ic_hwc, -isc_hwc) find the PC most often in the code that has to be fetched from memory when it is called. Use these to pinpoint functions that could be reorganized for better locality, or to see when automatic inlining has gone too far.
Most of the sample time bases listed in Table 4-3 are based on the R10000 event counters (see “Analyzing Performance with perfex” for an overview, and Appendix B, “R10000 Counter Event Types ” for details). Only the -usertime and -[f]pcsamp experiments can be run on other types of CPU.
Event counters can be programmed to generate an interrupt after counting a specific number of events. For example, if you choose the -gi_hwc sample time base, ssrun programs Counter 0 Event 15, graduated instructions, to overflow after 32,771 counts. Each time the counter overflows, the CPU traps to an interrupt routine, which samples the program state, reloads the counter, and restarts the program. The most commonly useful counters can be used directly with the ssrun options listed in Table 4-3.
It is easy to perform a sampling experiment. Example 4-4 shows running an experiment on program adi2.f.
Example 4-4. Performing an ssrun Experiment
% ssrun -fpcsamp adi2 Time: 7.619 seconds Checksum: 5.6160428338E+06 |
The output file of samples is left in a file with a default name compounded from the subject program name, the timebase option, and the process ID to ensure uniqueness. (The exact rules for the output filename are spelled out in man page speedshop(1) .) The output of Example 4-4 might leave a file named adi2.fpcsamp.m9076.
You can specify part of the name of the output file. (This is important when, for example, you are automating an experiment with a shell script.) You do this by putting the desired filename and directory in environment variables. The shell script ssruno, shown in Example C-6, runs an experiment with the output directory and base filename specified. Example 4-5 shows possible output from the use of ssruno.
Example 4-5. Example Run of ssruno
% ssruno -d /var/tmp -o adi2 -cy_hwc adi2 ssrun -cy_hwc adi2 ... ...... ssrun ends. -rw-r--r-- 1 guest guest 18480 Dec 17 16:25 /var/tmp/adi2.m5227 |
In addition to the experiment types listed in Table 4-3, a catchall experiment type, -prof_hwc, permits you to design an experiment that uses as its time base, any R10000 counter and any overflow value. You specify the counter number and overflow value using environment variables. (See the speedshop(1) man page for details.)
As an example, one countable event is an update to a shared cache line (see “Store or Prefetch-Exclusive to Shared Block in Scache (Event 31)” in Appendix B). A high number of these events in a perfex run would lead you to suspect the program is being slowed by memory contention for shared cache lines. But where in the program are the conflicting memory accesses occurring? You can perform an ssrun sampling experiment based on -prof_hwc, setting the following environment variables:
_SPEEDSHOP_HWC_COUNTER_NUMBER to 31
_SPEEDSHOP_HWC_COUNTER_OVERFLOW should be set to a count that will produce at least 100 samples during the run of the program—in other words, the total count that perfex reports for event 31, divided by 100 or more.
This experiment will tend to find the program in those statements that update shared cache lines; hence it should highlight the code that suffers from memory contention.
The output of any SpeedShop experiment is a trace file whose contents are binary samples of program state. You always use the prof command to display information about the program run, based on a trace file. Although it can produce a variety of reports, prof by default displays a list of routines (functions and procedures), ordered from the routine with the most samples to ones with the fewest. An example of a default report appears in Example 4-6.
Example 4-6. Default prof Report from ssrun Experiment
% prof adi2.fpcsamp.4885]
-------------------------------------------------------------------------------
Profile listing generated Sat Jan 4 10:28:11 1997
with: prof adi2.fpcsamp.4885
-------------------------------------------------------------------------------
samples time CPU FPU Clock N-cpu S-interval Countsize
8574 8.6s R10000 R10010 196.0MHz 1 1.0ms 2(bytes)
Each sample covers 4 bytes for every 1.0ms ( 0.01% of 8.5740s)
-------------------------------------------------------------------------------
-p[rocedures] using pc-sampling.
Sorted in descending order by the number of samples in each procedure.
Unexecuted procedures are excluded.
-------------------------------------------------------------------------------
samples time(%) cum time(%) procedure (dso:file)
6688 6.7s( 78.0) 6.7s( 78.0) zsweep (adi2:adi2.f)
671 0.67s( 7.8) 7.4s( 85.8) xsweep (adi2:adi2.f)
662 0.66s( 7.7) 8s( 93.6) ysweep (adi2:adi2.f)
208 0.21s( 2.4) 8.2s( 96.0) fake_adi (adi2:adi2.f)
178 0.18s( 2.1) 8.4s( 98.1) irand_ (/usr/lib32/libftn.so:../../libF77/rand_.c)
166 0.17s( 1.9) 8.6s(100.0) rand_ (/usr/lib32/libftn.so:../../libF77/rand_.c)
1 0.001s( 0.0) 8.6s(100.0) __oserror (/usr/lib32/libc.so.1:oserror.c)
8574 8.6s(100.0) 8.6s(100.0) TOTAL
|
Even this simple profile makes it clear that, in this program, you should focus on the routine zsweep, because it consumes over 80% of the run time of the program.
For finer detail, use the -heavy (or simply -h) option. This supplements the basic report with a list of individual source line numbers, ordered by frequency, as shown in Example 4-7.
Example 4-7. Profile at the Source Line Level Using prof -heavy
-------------------------------------------------------------------------------
-h[eavy] using pc-sampling.
Sorted in descending order by the number of samples in each line.
Lines with no samples are excluded.
-------------------------------------------------------------------------------
samples time(%) cum time(%) procedure (file:line)
3405 3.4s( 39.7) 3.4s( 39.7) zsweep (adi2.f:122)
3226 3.2s( 37.6) 6.6s( 77.3) zsweep (adi2.f:126)
425 0.42s( 5.0) 7.1s( 82.3) xsweep (adi2.f:80)
387 0.39s( 4.5) 7.4s( 86.8) ysweep (adi2.f:101)
273 0.27s( 3.2) 7.7s( 90.0) ysweep (adi2.f:105)
246 0.25s( 2.9) 8s( 92.9) xsweep (adi2.f:84)
167 0.17s( 1.9) 8.1s( 94.8) irand_ (../../libF77/rand_.c:62)
163 0.16s( 1.9) 8.3s( 96.7) fake_adi (adi2.f:18)
160 0.16s( 1.9) 8.5s( 98.6) rand_ (../../libF77/rand_.c:69)
45 0.045s( 0.5) 8.5s( 99.1) fake_adi (adi2.f:59)
32 0.032s( 0.4) 8.5s( 99.5) zsweep (adi2.f:113)
21 0.021s( 0.2) 8.5s( 99.7) zsweep (adi2.f:121)
11 0.011s( 0.1) 8.6s( 99.8) irand_ (../../libF77/rand_.c:63)
6 0.006s( 0.1) 8.6s( 99.9) rand_ (../../libF77/rand_.c:67)
4 0.004s( 0.0) 8.6s(100.0) zsweep (adi2.f:125)
1 0.001s( 0.0) 8.6s(100.0) ysweep (adi2.f:104)
1 0.001s( 0.0) 8.6s(100.0) ysweep (adi2.f:100)
1 0.001s( 0.0) 8.6s(100.0) __oserror (oserror.c:127)
8574 8.6s(100.0) 8.6s(100.0) TOTAL
|
From this listing it is clear that lines 112 and 116 warrant close inspection. Even finer detail can be obtained with the -source option, which lists the source code and disassembled machine code, indicating sample hits on specific instructions.
The other type of profiling is called ideal time, or basic block, profiling. (A basic block is a compiler term for any section of code that has only one entrance and one exit. Any program can be decomposed into basic blocks.) An ideal time profile is not based on statistical sampling. Instead, it is based on an exact count of the number of times each basic block in the program is entered during a run.
To create an ideal profile, ssrun copies the executable program and modifies the copy to contain code that records the entry to each basic block. Not only the executable itself but all the dynamic shared objects (standard libraries linked at run time) used by the program are also copied and instrumented. The instrumented executable and libraries are linked statically and run. The output trace file contains precise counts of program execution. Example 4-8 shows an ideal time experiment run.
Example 4-8. Ideal Time Profile Run
% ssrun -ideal adi2
Beginning libraries
/usr/lib32/libssrt.so
/usr/lib32/libss.so
/usr/lib32/libfastm.so
/usr/lib32/libftn.so
/usr/lib32/libm.so
/usr/lib32/libc.so.1
Ending libraries, beginning "adi2"
Time: 8.291 seconds
Checksum: 5.6160428338E+06
|
The number of times each basic block is encountered is recorded in an experiment file, which is named according to the usual rules of ssrun (see “Performing ssrun Experiments”).
The ideal time trace file is displayed using prof, just as for a sampled run. The default report lists every routine the program calls, including library routines. The report is ordered by the exclusive ideal time, from most to least. An example, edited to shorten the display, is shown in Example 4-9.
Example 4-9. Default Report of Ideal Time Profile
%prof adi2.ideal.m5064
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 11:42:33 1998
prof adi2.ideal.m5064
adi2 (n32): Target program
ideal: Experiment name
it:cu: Marching orders
R10000 / R10010: CPU / FPU
16: Number of CPUs
250: Clock frequency (MHz.)
Experiment notes--
From file adi2.ideal.m5064:
Caliper point 0 at target begin, PID 5064
/usr/people/cortesi/ADI/adi2.pixie
Caliper point 1 at exit(0)
-------------------------------------------------------------------------
Summary of ideal time data (ideal)--
1091506962: Total number of instructions executed
1218887512: Total computed cycles
4.876: Total computed execution time (secs.)
1.117: Average cycles / instruction
-------------------------------------------------------------------------
Function list, in descending order by exclusive ideal time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% cycles instructions calls function (dso: file, line)
[1] 1.386 28.4% 28.4% 346619904 304807936 32768 xsweep (adi2: adi2.f, 71)
[2] 1.386 28.4% 56.9% 346619904 304807936 32768 ysweep (adi2: adi2.f, 92)
[3] 1.386 28.4% 85.3% 346619904 304807936 32768 zsweep (adi2: adi2.f, 113)
[4] 0.540 11.1% 96.4% 135022759 111785107 1 fake_adi (adi2: adi2.f, 1)
[5] 0.101 2.1% 98.5% 25165824 35651584 2097152 rand_ (libftn.so...)
[6] 0.067 1.4% 99.8% 16777216 27262976 2097152 irand_ (libftn.so...)
[7] 0.002 0.0% 99.9% 505881 589657 1827 general_find_symbol (...)
[8] 0.001 0.0% 99.9% 364927 378813 3512 resolve_relocations (...)
[9] 0.001 0.0% 99.9% 214140 185056 1836 elfhash (rld: obj.c, 1211)
[10] 0.001 0.0% 99.9% 164195 182151 1846 find_symbol_in_object (...)
[11] 0.001 0.0% 99.9% 132844 177140 6328 obj_dynsym_got (...)
[12] 0.000 0.0% 100.0% 95570 117237 1804 resolving (rld: rld.c, 1893)
[13] 0.000 0.0% 100.0% 90941 112852 1825 resolve_symbol (rld:...)
[14] 0.000 0.0% 100.0% 86891 211175 3990 strcmp (rld: strcmp.s, 34)
[15] 0.000 0.0% 100.0% 75092 77499 1 fix_all_defineds (...)
[16] 0.000 0.0% 100.0% 67523 57684 9054 next_obj (rld: rld.c, 2712)
[17] 0.000 0.0% 100.0% 65813 59722 6 search_for_externals (...)
[18] 0.000 0.0% 100.0% 53431 73229 1780 find_first_object_to_search
[19] 0.000 0.0% 100.0% 42153 35668 3243 obj_set_dynsym_got (...)
[20] ...
|
The key information items in a report like the one in Example 4-9 are:
The exact count of machine instructions executed by the code of each function or procedure
The percentage of the total execution cycles consumed in each function or procedure
An ideal profile shows precisely which statements are most often executed, giving you an exact view of the algorithmic complexity of the program. However, an ideal profile is based on the ideal, or standard, time that each instruction ought to take. It does not necessarily reflect where a program spends elapsed time. The profile cannot take into account the ability of the CPU to overlap instructions, which can shorten the elapsed time. More important, it cannot take into account instruction delays caused by cache and TLB misses, which can greatly lengthen elapsed time.
The assumption of ideal time explains why the results of the profile in Example 4-9 are so startlingly different from that of the sampling profile of the same program in Example 4-6. From Example 4-9 you would expect zsweep to take exactly the same amount of run time as ysweep or xsweep—the instruction counts, and hence ideal times, are identical. Yet when sampling is used, zsweep takes ten times as much time as the other procedures.
The only explanation for such a difference is that some of the instructions in zsweep take longer than the ideal time to execute, so that the sampling run is more likely to find the PC in zsweep. The inference is that the code of zsweep encounters many more cache misses, or possibly TLB misses, than the rest of the program. (On machines without the R10000 CPU's hardware profiling registers, such a comparison is the only profiling method that can identify cache problems.)
It is quickly apparent that only the first few lines of the ideal time report are useful for tuning. The dozens of library functions the program called are of little interest. You can eliminate the clutter from the report by applying the -quit option to cut the report off after showing functions that used significant time, as shown in edited form in Example 4-10.
Example 4-10. Ideal Time Report Truncated with -quit
%prof -q 2% adi2.ideal.m5064
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 12:58:57 1998
prof -q 2% adi2.ideal.m5064
...
Summary of ideal time data (ideal)--
1091506962: Total number of instructions executed
1218887512: Total computed cycles
4.876: Total computed execution time (secs.)
1.117: Average cycles / instruction
-------------------------------------------------------------------------
Function list, in descending order by exclusive ideal time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% cycles instructions calls function (dso: file, line)
[1] 1.386 28.4% 28.4% 346619904 304807936 32768 xsweep (adi2: adi2.f, 71)
[2] 1.386 28.4% 56.9% 346619904 304807936 32768 ysweep (adi2: adi2.f, 92)
[3] 1.386 28.4% 85.3% 346619904 304807936 32768 zsweep (adi2: adi2.f, 113)
[4] 0.540 11.1% 96.4% 135022759 111785107 1 fake_adi (adi2: adi2.f, 1)
[5] 0.101 2.1% 98.5% 25165824 35651584 2097152 rand_ ( )
|
The -heavy option appends a list of source lines, sorted by their consumption of ideal instruction cycles. The combination of -q and -h is shown in Example 4-11.
Example 4-11. Ideal Time Report by Lines
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 13:03:06 1998
prof -h -q 2% adi2.ideal.m5064
...
-------------------------------------------------------------------------
Function list, in descending order by exclusive ideal time
-------------------------------------------------------------------------
...function list same as Example 4-10...
------------------------------------------------------------------------
Line list, in descending order by time
-------------------------------------------------------------------------
excl.secs % cum.% cycles invocations function (dso: file, line)
0.565 11.6% 11.6% 141273180 4161536 xsweep (adi2: adi2.f, 80)
0.565 11.6% 23.2% 141273180 4161536 ysweep (adi2: adi2.f, 101)
0.565 11.6% 34.8% 141273180 4161536 zsweep (adi2: adi2.f, 122)
0.552 11.3% 46.1% 137925189 4161536 xsweep (adi2: adi2.f, 84)
0.552 11.3% 57.4% 137925189 4161536 ysweep (adi2: adi2.f, 105)
0.552 11.3% 68.7% 137925189 4161536 zsweep (adi2: adi2.f, 126)
0.196 4.0% 72.7% 49041090 2097152 fake_adi (adi2: adi2.f, 59)
0.194 4.0% 76.7% 48416848 2097152 fake_adi (adi2: adi2.f, 18)
0.152 3.1% 79.8% 37948124 4161536 xsweep (adi2: adi2.f, 79)
0.152 3.1% 82.9% 37948124 4161536 ysweep (adi2: adi2.f, 100)
0.152 3.1% 86.1% 37948124 4161536 zsweep (adi2: adi2.f, 121)
0.116 2.4% 88.4% 28896699 4161536 ysweep (adi2: adi2.f, 104)
0.116 2.4% 90.8% 28896699 4161536 zsweep (adi2: adi2.f, 125)
0.116 2.4% 93.2% 28896699 4161536 xsweep (adi2: adi2.f, 83)
|
You can use the -lines option instead of -heavy. This lists the source lines in their source sequence, grouped by procedure, with the procedures ordered by decreasing time. This option helps you see the expensive statements in their context. However, the option does not combine well with the -q option. In order to use -lines yet avoid voluminous output, choose specific procedures that you want to analyze and restrict the display to only those procedures using -only, as shown in Example 4-12.
Example 4-12. Ideal Time Profile Using -lines and -only Options
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 13:16:54 1998
prof -l -only zsweep -o xsweep adi2.ideal.m5064
...
-------------------------------------------------------------------------
Function list, in descending order by exclusive ideal time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% cycles instructions calls function (dso: file, line)
[1] 1.386 28.4% 28.4% 346619904 304807936 32768 xsweep (adi2: adi2.f, 71)
[2] 1.386 28.4% 56.9% 346619904 304807936 32768 zsweep (adi2: adi2.f, 113)
-------------------------------------------------------------------------
Line list, in descending order by function-time and then line number
-------------------------------------------------------------------------
excl.secs excl.% cum.% cycles invocations function (dso: file, line)
0.002 0.0% 0.0% 412872 32768 xsweep (adi2: adi2.f, 71)
0.152 3.1% 3.1% 37948124 4161536 xsweep (adi2: adi2.f, 79)
0.565 11.6% 14.7% 141273180 4161536 xsweep (adi2: adi2.f, 80)
0.116 2.4% 17.1% 28896699 4161536 xsweep (adi2: adi2.f, 83)
0.552 11.3% 28.4% 137925189 4161536 xsweep (adi2: adi2.f, 84)
0.001 0.0% 28.4% 163840 32768 xsweep (adi2: adi2.f, 87)
0.002 0.0% 28.5% 412872 32768 zsweep (adi2: adi2.f, 113)
0.152 3.1% 31.6% 37948124 4161536 zsweep (adi2: adi2.f, 121)
0.565 11.6% 43.2% 141273180 4161536 zsweep (adi2: adi2.f, 122)
0.116 2.4% 45.5% 28896699 4161536 zsweep (adi2: adi2.f, 125)
0.552 11.3% 56.9% 137925189 4161536 zsweep (adi2: adi2.f, 126)
0.001 0.0% 56.9% 163840 32768 zsweep (adi2: adi2.f, 129)
|
Any simple relationship between source statement numbers and the executable code is destroyed during optimization. The statement numbers listed in a profile correspond very nicely to the source code when the program was compiled without optimization (-O0 compiler option). When the program was compiled with optimization, the source statement numbers in the profile are approximate, and you may have difficulty relating the profile to the code.
The information in an ideal-time profile includes exact counts of how often every conditional branch was taken or not taken. The compiler can use this information to generate optimal branch code. You use prof to extract the branch statistics into a compiler feedback file using the -feedback option:
prof -feedback program.ideal.m5064 |
The usual display is produced on standard output, but prof also writes a program.cfb file. You provide this as input to the compiler using the -fb compiler option, as described in “Passing a Feedback File” in Chapter 5.
Because ideal profiling counts the instructions executed by the program, it can provide all sorts of interesting information about the program. Use the -archinfo option to get a detailed census of the most arcane details of the program's execution. An edited version is shown in Example 4-13.
Example 4-13. Ideal Time Architecture Information Report
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 13:34:40 1998
prof -archinfo adi2.ideal.m5064
...
Integer register usage
----------------------
register use count % base count % dest. count %
r00 342234300 17.76% 0 0.00% 4334788 0.22%
r01 10878870 0.56% 29178987 1.51% 2223380 0.12%
r02 59266446 3.08% 41971 0.00% 2308302 0.12%
r03 ...
Floating-point register usage
-----------------------------
register use count % dest. count %
f00 62521432 27.29% 6291491 2.75%
f01 37552180 16.39% 14581780 6.36%
f02 29163562 12.73% 21 0.00%
f03 ...
Instruction execution statistics
--------------------------------
1091506962: instructions executed
56230002: floating point operations (11.5331 Mflops @ 250 MHz)
400759124: integer operations (82.1977 M intops @ 250 MHz)
...
Instruction counts
------------------
Name executions exc. % cum. % instructions inst. % cum.%
lw 303415993 28.69% 28.69% 1415 12.93% 12.93%
addiu 115696249 10.94% 39.64% 992 9.07% 22.00%
addu 96419728 9.12% 48.75% 352 3.22% 25.22%
...
madd.d 12484612 1.18% 93.82% 5 0.05% 50.54%
...
|
Among the points to be learned with -archinfo are these:
The count and average rate of floating-point operations. Note that these counts differ from the ones reported by perfex. R10000 Event 21 counts floating-point instructions, not floating point operations. The multiply-add instruction carries out two floating-point operations; perfex counts it as 1 and prof as 2.
The count and average rate of integer operations, allowing you to judge whether these (such as index calculations) are important to performance.
Exact counts of specific opcodes executed, including a tally of those troublesome multiply-add (madd.d) instructions.
The profiles discussed so far do not reflect the call hierarchy of the program. If the routine zsweep were called from two different locations, you could not tell how much time resulted from the calls at each location; you only know the total time spent in zsweep. If you could learn that, say, most of the calls came from the first location, it would affect how you tuned the program. For example, you might try inlining the call to the first location, but not the second. Or, if you want to parallelize the program, knowing that the first location is where most of the time is spent, you might consider parallelizing the calls to zsweep, rather than trying to parallelize the zsweep routine itself.
Only two types of SpeedShop profiles capture sufficient information to reveal the call hierarchy: ideal counting and usertime sampling.
You can request call hierarchy information in an ideal time report using the -butterfly flag (and the -q flag to reduce clutter). This produces the usual report (like Example 4-10), with an additional section which, in the prof(1) man page, is called the “butterfly report.” An edited extract of a butterfly report is shown in Example 4-14.
Example 4-14. Extract from a Butterfly Report
-----------------------------------------------------------
99.8% 4.867(0000001) 4.867 __start [1]
[2] 99.8% 4.867 0.0% 0.000 main [2]
99.8% 4.867(0000001) 4.867 fake_adi [3]
0.0% 0.000(0000005) 0.000 signal [125]
-----------------------------------------------------------
99.8% 4.867(0000001) 4.867 main [2]
[3] 99.8% 4.867 11.1% 0.540 fake_adi [3]
28.4% 1.386(0032768) 1.386 zsweep [4]
28.4% 1.386(0032768) 1.386 ysweep [6]
28.4% 1.386(0032768) 1.386 xsweep [5]
3.4% 0.168(2097152) 0.168 rand_ [7]
0.0% 0.000(0000002) 0.000 e_wsfe [63]
0.0% 0.000(0000002) 0.000 s_wsfe64 [68]
0.0% 0.000(0000001) 0.000 do_fioxr8v [84]
0.0% 0.000(0000001) 0.000 do_fioxr4v [83]
0.0% 0.000(0000001) 0.000 s_stop [86]
0.0% 0.000(0000002) 0.000 dtime_ [183]
-----------------------------------------------------------
28.4% 1.386(0032768) 4.867 fake_adi [3]
[4] 28.4% 1.386 28.4% 1.386 zsweep [4]
-----------------------------------------------------------
28.4% 1.386(0032768) 4.867 fake_adi [3]
[5] 28.4% 1.386 28.4% 1.386 xsweep [5]
-----------------------------------------------------------
28.4% 1.386(0032768) 4.867 fake_adi [3]
[6] 28.4% 1.386 28.4% 1.386 ysweep [6]
-----------------------------------------------------------
3.4% 0.168(2097152) 4.867 fake_adi [3]
[7] 3.4% 0.168 2.1% 0.101 rand_ [7]
1.4% 0.067(2097152) 0.067 irand_ [8]
|
There is a block of information for each routine in the program. A number, shown in brackets (for example, [3]), is assigned to each routine for reference. Examine the second, and largest, section in Example 4-14, the one for routine fake_adi.
The line that begins and ends with the reference number (in this example, [3]) describes the routine itself. It resembles the following:
[3] 99.8% 4.867 11.1% 0.540 fake_adi [3] |
From left to right it shows:
The total run time attributed to this routine and its descendants, as a percentage of program run time and as a count (99.8% and 4.867 seconds).
The amount of run time that was consumed in the code of the routine itself. In this example, the routine code accounted for 11.1% of the run time, or 0.54 seconds. The remaining 88.7% of the time was spent in subroutines that it called.
The name of the routine in question is fake_adi.
The lines that precede this line describe the places that called fake_adi. In the example there was only one such place, so only one line appears, resembling the following:
99.8% 4.867(0000001) 4.867 main [2] |
From left to right, it shows:
All calls made to fake_adi from this location consumed 99.8%, or 4.867 seconds, of run time.
How many calls were made from this location (just 1, in this case).
How much time was consumed by this calling routine and its descendents.
The name of the calling routine, in this case, main.
The reference number is 2.
When a routine is called from more than one place, these lines show you which locations made the most calls, and how much time the calls from each location cost. This lets you zero in on the important callers and neglect the minor ones.
The lines that follow the central line show the calls this routine makes, and how its time is distributed among them. In Example 4-14, routine fake_adi calls 10 other routines, but the bulk of the ideal time is divided among the first three. These lines let you home in on precisely those subroutines that account for the most time, and ignore the rest.
The butterfly report tells you not just which subroutines are consuming the most time, but which execution paths in the program are consuming time. This lets you decide whether you should try to optimize a subroutine, inline the subroutine, or try to eliminate some calls to the subroutine, or redesign the algorithm. For example, suppose you find that the bulk of calls to a general-purpose subroutine come from one place, and on examining that call, you find that all the calls are for one simple case. You could either replace the call with in-line code, or you could add a special-purpose subroutine to handle that case very quickly.
The limitation of this report is that it is based on ideal time, and so does not reflect costs due to cache misses and other elapsed-time delays.
To get a hierarchical profile that accounts for elapsed time, use usertime sampling instead of ideal time. As shown in Table 4-3, a -usertime experiment samples the state of the program every 30 ms. Each sample records the location of the program counter and the entire call stack, showing which routines have been called to reach this point in the program. From this trace data a hierarchical profile can be constructed. (Other sampling experiments record only the PC, not the entire call stack.)
You take a -usertime sample exactly like any other ssrun experiment (see “Performing ssrun Experiments”). The result for sample program adi2 (edited for brevity) is shown in Example 4-15.
Example 4-15. Usertime Call Hierarchy
% ssrun -usertime adi2
Time: 8.424 seconds
Checksum: 5.6160428338E+06
% prof -butterfly adi2.usertime.m6836
-------------------------------------------------------------------------
SpeedShop profile listing generated Thu Jun 25 16:28:27 1998
prof -butterfly adi2.usertime.m6836
...
-------------------------------------------------------------------------
Summary of statistical callstack sampling data (usertime)--
305: Total Samples
0: Samples with incomplete traceback
9.150: Accumulated Time (secs.)
30.0: Sample interval (msecs.)
-------------------------------------------------------------------------
Function list, in descending order by exclusive time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% incl.secs incl.% samples procedure (dso: file, line)
[4] 5.670 62.0% 62.0% 5.670 62.0% 189 zsweep (adi2: adi2.f, 113)
[5] 1.410 15.4% 77.4% 1.410 15.4% 47 xsweep (adi2: adi2.f, 71)
[6] 1.380 15.1% 92.5% 1.380 15.1% 46 ysweep (adi2: adi2.f, 92)
[1] 0.510 5.6% 98.0% 9.150 100.0% 305 fake_adi (adi2: adi2.f, 1)
[8] 0.120 1.3% 99.3% 0.120 1.3% 4 irand_ (libftn.so: rand_.c, 62)
[7] 0.060 0.7% 100.0% 0.180 2.0% 6 rand_ (libftn.so: rand_.c, 67)
[2] 0.000 0.0% 100.0% 9.150 100.0% 305 __start (adi2: crt1text.s, 103)
[3] 0.000 0.0% 100.0% 9.150 100.0% 305 main (libftn.so: main.c, 76)
-------------------------------------------------------------------------
Butterfly function list, in descending order by inclusive time
...
-----------------------------------------------------
100.0% 9.150 9.150 main
[1] 100.0% 9.150 5.6% 0.510 fake_adi [1]
62.0% 5.670 5.670 zsweep
15.4% 1.410 1.410 xsweep
15.1% 1.380 1.380 ysweep
2.0% 0.180 0.180 rand_
-----------------------------------------------------
62.0% 5.670 9.150 fake_adi
[4] 62.0% 5.670 62.0% 5.670 zsweep [4]
-----------------------------------------------------
15.4% 1.410 9.150 fake_adi
[5] 15.4% 1.410 15.4% 1.410 xsweep [5]
-----------------------------------------------------
15.1% 1.380 9.150 fake_adi
[6] 15.1% 1.380 15.1% 1.380 ysweep [6]
-----------------------------------------------------
2.0% 0.180 9.150 fake_adi
[7] 2.0% 0.180 0.7% 0.060 rand_ [7]
1.3% 0.120 0.120 irand_
-----------------------------------------------------
1.3% 0.120 0.180 rand_
[8] 1.3% 0.120 1.3% 0.120 irand_ [8]
|
The information is less detailed than an ideal time profile (only 305 samples over this entire run), but it reflects elapsed time. Compare the butterfly report section for routine fake_adi in Example 4-15 to the same section in Example 4-14. When actual time differs so much from ideal time, something external to the algorithm is delaying execution. We will investigate this problem later (see “Identifying Cache Problems with Perfex and SpeedShop” in Chapter 6.)
A program can handle floating-point exceptions using the handle_sigfpes library procedure (documented in the sigfpe(3) man pages). Many programs do not handle exceptions. If exceptions occur, they still cause hardware traps that are ignored in software. A high number of ignored exceptions can cause a program to run slowly for no apparent reason.
The ssrun experiment type -fpe creates a trace file that records all floating-point exceptions. Use prof to display the data as usual. The report shows the procedures and lines that caused exceptions. In effect, this is a sampling profile in which the sampling time base is the occurrence of an exception.
Use exception profiling to verify that a program does not have significant exceptions. When you know that, you can safely set a higher level of exception handling via the compiler flag -TENV (see “Permitting Speculative Execution” in Chapter 5).
When a program does generate a significant number of undetected exceptions, the exceptions are likely to be floating-point underflows (a program is not likely to get through functional testing if it suffers a large number of divide-by-zero, overflow, or invalid operation exceptions). A large number of underflows causes performance problems because each exception generates a trap to the kernel to finish the calculation by setting the result to zero. Although the results are correct, excess system time elapses. On R8000 based systems, the default is to flush underflows to zero in the hardware, avoiding the trap. However, R10000, R5000, and R4400 systems default to trapping on underflow.
If underflow detection is not required for numerical accuracy, underflows can be flushed to zero in hardware. This can be done by methods described in detail in man page sigfpe(3C) . The simplest method is to link in the floating point exception library, libfpe, and at run time to set the TRAP_FPE environment variable to the string UNDERFL=FLUSH_ZERO.
The hardware bit that controls how underflows are handled is located in a part of the R10000 floating-point unit called the floating-point status register (FSR). In addition to setting the way underflows are treated, this register also selects which IEEE rounding mode is used and which IEEE exceptions are enabled (that is, not ignored). Furthermore, it contains the floating-point condition bits, which are set by floating-point compare instructions, and the cause bits, which are set when any floating-point exception occurs. The details of the FSR are documented in the MIPS R10000 Microprocessor User Guide listed in “Related Manuals”. You can gain programmed access to the FSR using functions described in man page sigfpe(3C) . However, to do so makes your program hardware-dependent.
Speedshop and perfex profile the execution path, but there is a second dimension to program behavior: data references.
Both dimensions are sketched in Figure 4-1. The program executes up and down through the program text. An execution profile depicts the average intensity of the program's residence at any point, but execution moves constantly. At the same time, the program constantly refers to locations in its data.
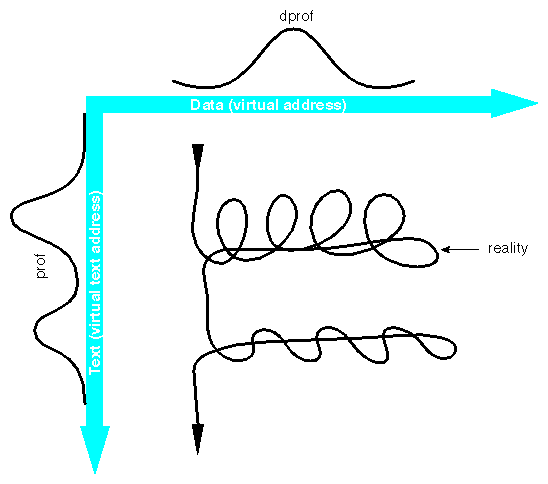
You can use dprof to profile the intensity with which the program uses data memory locations, showing the alternate dimension to that shown by prof. You can use dlook to find out where in the SN0 architecture the operating system placed a program's pages.
The dprof tool, like ssrun, executes a program and samples the program while it runs. Unlike ssrun, dprof does not sample the PC and stack. It samples the current operand address of the interrupted instruction. It accumulates a histogram of access to data addresses, grouped in units of virtual page. Example 4-16 shows an application of dprof to the test program.
Example 4-16. Application of dprof
% dprof -hwpc -out adi2.dprof adi2 Time: 27.289 seconds Checksum: 5.6160428338E+06 % ls -l adi2.dprof -rw-r--r-- 1 guest 40118 Dec 18 18:54 adi2.dprof % cat adi2.dprof -------------------------------------------------- address thread reads writes -------------------------------------------------- 0x0010012000 0 1482 0 0x007eff4000 0 59075 1462 0x007eff8000 0 57 22 0x007effc000 0 69 15 0x007f000000 0 75 18 0x007f004000 0 58 10 0x007f008000 0 65 13 0x007f00c000 0 64 20 0x007f010000 0 76 22 ... 0x007ffe0000 0 59 16 0x007ffe4000 0 70 9 0x007ffe8000 0 57 11 0x007ffec000 0 53 8 0x007fff0000 0 56 14 0x007fff4000 0 36 1 |
Each line contains a count of all references to one virtual memory page from one IRIX process (this program has only one process). Note that the addresses at the left increment by 0x04000, or 16 KB, the default size of a virtual page in larger systems under IRIX 6.5.
The dprof report is based on statistical sampling; it does not record all references. The time base is either the interval timer (option -itimer) or the R10000 event cycle counter (option -hwpc, available only to an R10000 CPU). Other time base options are supported; see the dprof(1) man page.
At the default interrupt frequency using the cycle counter, samples are taken of only 1 instruction in 10,000. This produces a coarse sample that is not likely to be repeatable from run to run. However, even this sampling rate slows program execution by almost a factor of three. You can obtain a more detailed sample by specifying a shorter overflow count (option -ovfl n), but this will extend program execution time proportionately.
The coarse histogram is useful for showing which pages are used. For example, you can plot the data as a histogram. Using gnuplot (which is available on the SGI Freeware CDROM), a simple plot of total access density, as shown in Figure 4-2, is obtained as follows:
% /usr/freeware/bin/gnuplot
G N U P L O T
unix version 3.5
patchlevel 3.50.1.17, 27 Aug 93
last modified Fri Aug 27 05:21:33 GMT 1993
Copyright(C) 1986 - 1993 Thomas Williams, Colin Kelley
Send comments and requests for help to info-gnuplot@dartmouth.edu
Send bugs, suggestions and mods to bug-gnuplot@dartmouth.edu
Terminal type set to 'x11'
gnuplot> set logscale y
gnuplot> plot "<tail +4 adi2.dprof|awk '{print NR,$3+$4,$2}'" with box
|
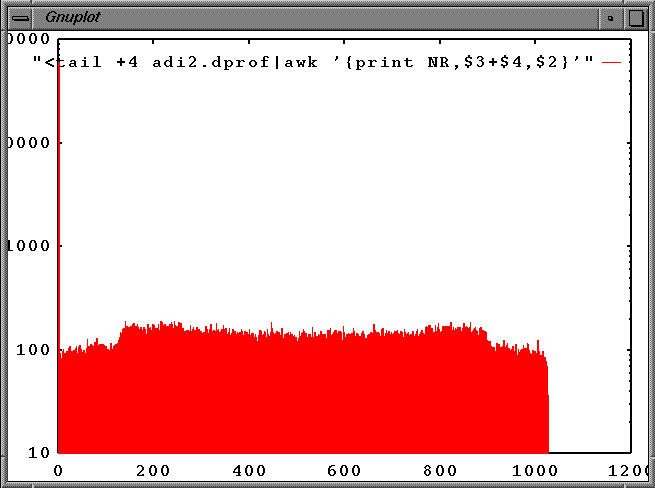
The information provided by dprof is not of great benefit to a single-threaded application. But for multithreaded applications, such as OpenMP programs, it can reveal a lot. Because access to the local memory is faster than access to remote memories on an SN0 system, the best performance on parallel programs that sustain a lot of cache misses is achieved if each thread primarily accesses its local memory. dprof gives you the ability to analyze which regions of virtual memory each thread of a program accesses.
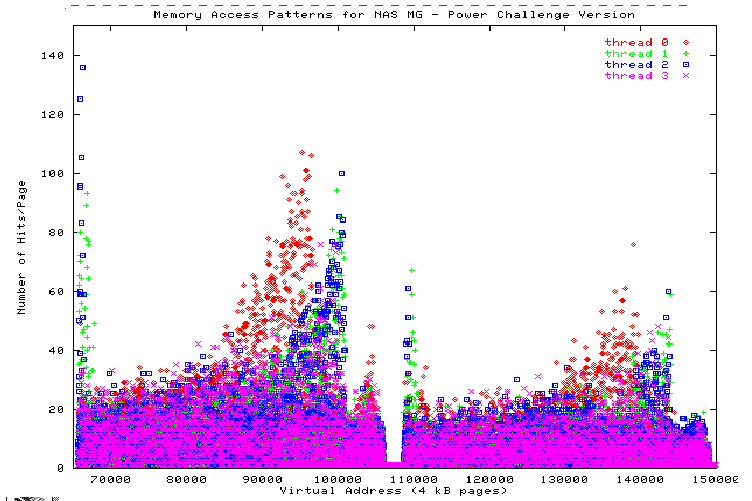
Figure 4-3 and Figure 4-4 show plots of the dprof output for two parallel programs. Figure 4-3 shows the memory accesses for the two main arrays in a four-threaded program. It is clear from the figure that the memory pages of the two arrays are being accessed nearly uniformly by the four threads. That is, there are no sections of the arrays that can be considered local to one thread. As a result, the majority of memory accesses are nonlocal and costly. To improve the performance of this program, the underlying algorithm needs to be modified so that each thread's accesses will be primarily local.
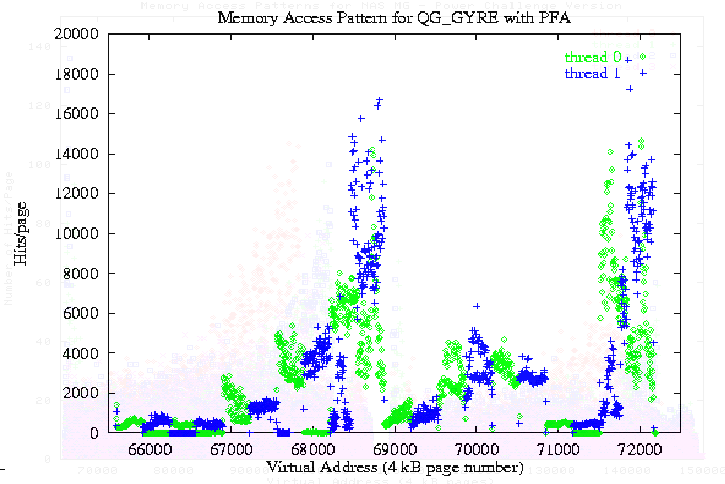
Contrast Figure 4-3 to Figure 4-4. In this two-threaded program (Figure 4-4), it is easy to see how the memory space is decomposed into pages accessed primarily by just one of the threads. For this program, the majority of memory references are local, and good performance is achieved.
The output of dprof can also be used as input to dplace; see “Assigning Memory Ranges” in Chapter 8.
The dlook program (see the dlook(1) man page), like perfex and dprof, takes a second program's command line as its argument. It executes that program, and monitors where the pages of text and data are located. At the end of the run, dlook writes a report on the memory placement to the standard error file, or to a file you specify. Example 4-17 shows the result of applying dlook with default options.
Example 4-17. Example of Default dlook Output
% dlook adi2
Time: 8.498 seconds
Checksum: 5.6160428338E+06
________________________________________________________________
Exit : "adi2" is process 1773 and at ~9.38 second is running on:
cpu 10 or /hw/module/6/slot/n3/node/cpu/a .
data/heap:
[0x00010010000,0x00010024000] 5 16K pages on /hw/module/6/slot/n3/node
stack:
[0x0007eff0000,0x0007fd80000] 868 16K pages on /hw/module/6/slot/n3/node
[0x0007fd80000,0x0007fff0000] 156 16K pages on /hw/module/6/slot/n1/node
[0x0007fff0000,0x0007fff8000] 2 16K pages on /hw/module/5/slot/n1/node
________________________________________________________________
|
The -mapped option produces a lengthy list of all memory-mapped regions (such regions are normally mapped by library code, not the program itself). The -sample n option produces a periodic report during the run, from which you could follow page migration.
Sometimes dlook reports a page as being located on device /hw/mem, instead of a particular module. This means that the page has been added to the program's virtual address space, but because the program has not yet touched the page, it has not been allocated to real memory.
You can record the dynamic behavior of a program in a number of different ways, simply, quickly, and without modifying the program. You can display the output of any experiment in different ways, revealing the execution “hot spots” in the code and the effect of its subroutine call structure. All the information you need in order to tune the algorithm is readily available.