This chapter provides two tutorials for using the SpeedShop tools to gather and analyze performance data in a Fortran program. There are three versions of the first program:
The linpack directory contains files for the n32-bit ABI.
The linpack64 directory contains files for the 64-bit ABI.
The linpacko32 directory contains files for the o32-bit ABI.
The first tutorial covers the following topics:
“Tutorial Overview”, introduces the sample program and explains the different scenarios in which it will be used.
“Tutorial Setup”, leads you through the necessary setup for running the experiment.
“Analyzing Performance Data”, steps you through different experiments, discussing first how to do the experiments, then how to interpret the results.
The second tutorial creates a Message Passing Interface (MPI) experiment. The experiment file is generated by SpeedShop and displayed by the WorkShop performance analyzer. See “MPI Tracing Tutorial”.
| Note: Because of inherent differences between systems and also due to concurrent processes that may be running on your system, your experiment will produce different results from the one in this tutorial. However, the basic structure of the results should be the same. |
The Fortran tutorial demonstrates the following experiments:
usertime
pcsamp
hardware counters
basic block count (bbcounts)
MPI trace experiment
For an example of a floating point exception experiment (fpe), see Chapter 2, “Tutorial for C Users”.
This tutorial is based on a standard benchmark program called linpackup. There are two versions of the program: the linpack directory contains files for the n32-bit ABI, and the linpacko32 directory contains files for the o32-bit ABI. Each linpack directory contains versions of the program for a single processor (linpackup) and for multiple processors (linpackd). When you work with the tutorial, choose the version of the program that is most appropriate for your system. A good guideline is to choose whichever version corresponds to the way you expect to develop your programs.
This tutorial was written and tested using the single-processor version of the program (linpackup) in the linpack directory.
The linpack program is a standard benchmark designed to measure CPU performance in solving dense linear equations. The program focuses primarily on floating-point performance.
Output from the linpackup program looks like the following:
.
.
.
norm. resid resid machep x(1) x(n)
5.35882395E+00 7.13873405E-13 2.22044605E-16 1.00000000E+00 1.00000000E+00
times are reported for matrices of order 300
dgefa dgesl total mflops unit ratio
times for array with leading dimension of 301
3.720E+00 4.000E-02 3.760E+00 4.835E+00 4.136E-01 6.714E+01
3.780E+00 3.000E-02 3.810E+00 4.772E+00 4.191E-01 6.804E+01
3.730E+00 4.000E-02 3.770E+00 4.822E+00 4.147E-01 6.732E+01
3.730E+00 4.000E-02 3.770E+00 4.822E+00 4.147E-01 6.732E+01
times for array with leading dimension of 300
3.800E+00 4.000E-02 3.840E+00 4.734E+00 4.224E-01 6.857E+01
3.810E+00 4.000E-02 3.850E+00 4.722E+00 4.235E-01 6.875E+01
3.770E+00 4.000E-02 3.810E+00 4.772E+00 4.191E-01 6.804E+01
3.782E+00 4.000E-02 3.822E+00 4.757E+00 4.205E-01 6.825E+01 |
Copy the program to a directory where you have write permission and compile it so that you can use it in the tutorial.
Change to the /usr/demos/SpeedShop directory.
Copy the appropriate linpack directory and its contents to a directory in which you have write permission:
% cp -r linpack your_dir
Change to the directory you just created:
% cd your_dir/linpack
Compile the program by entering:
% make all
This provides an executable for the experiment.

Note: You must APO installed in order to build these files. For sales and licensing information, contact your SGI sales representative.
This section lists the steps you need to perform the following experiments on the linpackup program, generate the experiment's results, and interpret the results:
The usertime experiment. It returns the CPU time used by each routine in your program. See “A usertime Experiment”.
The pcsamp experiment. It returns CPU time for each routine in your program. See “A pcsamp Experiment”.
The dsc_hwc (secondary data cache hardware counter) experiment. In a hardware counter experiment, the program counter is sampled every time a hardware counter exceeds a specified limit. In the experiment performed in this section, the hardware counter keeps track of the number of times a data item required in a calculation was not present in secondary data cache. When a data item is not in cache, it must be retrieved from memory, which is a more time-consuming process. See “A Hardware Counter Experiment”.
The bbcounts experiment. This experiment calculates the best time achievable. See “A bbcounts Experiment”.
This section lists the steps you need to perform a usertime experiment. The usertime experiment allows you to gather data on the amount of CPU time spent in each routine in your program. For more information, see “Call Stack Profiling Experiment (usertime/totaltime)” in Chapter 4.
From the command line, enter the following:
% ssrun -v -usertime linpackup |
This starts the experiment. The -v flag tells ssrun to print a log to stderr.
Output from linpackup and from ssrun is printed to stdout, as shown in the following example. A data file is also generated. The name consists of the process name (linpackup), the experiment type (usertime), and the experiment ID. In this example, the filename is linpackup.usertime.m12205.
ssrun: target PID 18819
ssrun: setenv _SPEEDSHOP_MARCHING_ORDERS ut:cu
ssrun: setenv _SPEEDSHOP_EXPERIMENT_TYPE usertime
ssrun: setenv _SPEEDSHOP_TARGET_FILE linpackup
ssrun: setenv _RLD_LIST libss.so:libssrt.so:DEFAULT
ssrun: setenv _RLDN32_LIST libss.so:libssrt.so:DEFAULT
ssrun: setenv _RLD64_LIST libss.so:libssrt.so:DEFAULT
Please send the results of this run to:
Jack J. Dongarra
Mathematics and Computer Science Division
Argonne National Laboratory
Argonne, Illinois 60439
Telephone: 312-972-7246
ARPAnet: DONGARRA@ANL-MCS
norm. resid resid machep x(1) x(n)
5.35882395E+00 7.13873405E-13 2.22044605E-16 1.00000000E+00
1.00000000E+00
times are reported for matrices of order 300
dgefa dgesl total mflops unit ratio
times for array with leading dimension of 301
3.010E+00 3.000E-02 3.040E+00 5.980E+00 3.344E-01 5.429E+01
3.010E+00 3.000E-02 3.040E+00 5.980E+00 3.344E-01 5.429E+01
3.010E+00 3.000E-02 3.040E+00 5.980E+00 3.344E-01 5.429E+01
3.010E+00 3.000E-02 3.040E+00 5.980E+00 3.344E-01 5.429E+01
times for array with leading dimension of 300
3.020E+00 3.000E-02 3.050E+00 5.961E+00 3.355E-01 5.446E+01
3.030E+00 3.000E-02 3.060E+00 5.941E+00 3.366E-01 5.464E+01
3.030E+00 3.000E-02 3.060E+00 5.941E+00 3.366E-01 5.464E+01
3.024E+00 3.000E-02 3.054E+00 5.953E+00 3.360E-01 5.454E+01 |
To generate a report on the data collected, enter the following at the command line:
% prof your_output_file_name > usertime.results |
The prof command interprets the type of experiment you have performed and prints results to stdout. The following report shows partial prof output.
| Note: Lines have been wrapped because of line width restrictions. |
-------------------------------------------------------------------------
SpeedShop profile listing generated Tue Mar 19 06:52:47 2002
prof linpackup.usertime.m18819
linpackup (n32): Target program
usertime: Experiment name
ut:cu: Marching orders
R5000 / R5000: CPU / FPU
1: Number of CPUs
180: Clock frequency (MHz.)
Experiment notes--
From file linpackup.usertime.m18819:
Caliper point 0 at target begin, PID 18819
/speedlin/linpack/linpackup
Caliper point 1 at exit(0)
-------------------------------------------------------------------------
Summary of statistical callstack sampling data (usertime)--
1960: Total Samples
0: Samples with incomplete traceback
58.800: Accumulated Time (secs.)
30.0: Sample interval (msecs.)
-------------------------------------------------------------------------
Function list, in descending order by exclusive time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% incl.secs incl.% samples procedure (dso: file, line)
[4] 54.600 92.9% 92.9% 54.600 92.9% 1820 daxpy (linpackup: linpackup.f, 495)
[5] 1.920 3.3% 96.1% 1.920 3.3% 64 matgen (linpackup: linpackup.f, 199)
[3] 1.800 3.1% 99.2% 56.250 95.7% 1875 dgefa (linpackup: linpackup.f, 221)
[7] 0.300 0.5% 99.7% 0.300 0.5% 10 idamax (linpackup: linpackup.f, 700)
[8] 0.120 0.2% 99.9% 0.120 0.2% 4 dscal (linpackup: linpackup.f, 670)
[9] 0.030 0.1% 99.9% 0.030 0.1% 1 dmxpy (linpackup: linpackup.f, 826)
[10] 0.030 0.1% 100.0% 0.030 0.1% 1 _type_f (libftn.so: fmt.c, 761)
[1] 0.000 0.0% 100.0% 58.800 100.0% 1960 main (libftn.so: main.c, 76)
[2] 0.000 0.0% 100.0% 58.800 100.0% 1960 linp (linpackup: linpackup.f, 3)
[6] 0.000 0.0% 100.0% 0.570 1.0% 19 dgesl (linpackup: linpackup.f, 324)
[11] 0.000 0.0% 100.0% 0.030 0.1% 1 do_fioxr8v (libftn.so: fmt.c, 1603)
[12] 0.000 0.0% 100.0% 0.030 0.1% 1 do_fio64_mp (libftn.so: fmt.c, 626) |
The report shows information for each function.
The index column, which enumerates the routines in the program, provides an index number for reference.
The excl.secs column shows how much time, in seconds, was spent in the routine itself (exclusive time).
The excl.% column shows the percentage of a program's total time that was spent in the function. For example, the daxpy routine consumed 92.9% of the program's time.
The cum.% column shows the percentage of the complete program time that has been spent in the routines that have been listed so far.
The incl.secs column shows how much time, in seconds, was spent in the function and descendents of the function.
The incl.% column shows the cumulative percentage of inclusive time spent in each routine and its descendents.
The samples column provides the number of samples taken from the function and all of its descendants.
The function (dso:file, line) column lists the routine name, its DSO name, its file name, and its line number.
| Note: Many functions shown here have only one or two hits. The data for those functions is not statistically significant. (Routines that begin with an underscore, such as __start, are internal routines that you cannot change.) |
This section lists the steps you need to perform a pcsamp experiment. The pcsamp experiment allows you to gather information on actual CPU time for each source code line, machine line, and function in your program. For more information on pcsamp, see “PC Sampling Experiment (pcsamp)” in Chapter 4.
From the command line, enter the following:
% ssrun -pcsamp linpackup |
This starts the experiment.
Output from linpackup and from ssrun is printed to stdout, as shown in the following example. A data file is also generated. The name consists of the process name (linpackup), the experiment type (pcsamp), and the experiment ID. In this example, the file name is linpackup.pcsamp.m12333.
.
norm. resid resid machep x(1) x(n)
5.35882395E+00 7.13873405E-13 2.22044605E-16 1.00000000E+00
1.00000000E+00
.
.
. |
To generate a report on the data collected, enter the following at the command line:
% prof your_output_file_name > pcsamp.results |
The prof command interprets the type of experiment you have performed and prints results to stdout. The following report shows partial prof output.
-------------------------------------------------------------------------
SpeedShop profile listing generated Tue Mar 19 07:02:22 2002
prof linpackup.pcsamp.m18866
linpackup (n32): Target program
pcsamp: Experiment name
pc,2,10000,0:cu: Marching orders
R5000 / R5000: CPU / FPU
1: Number of CPUs
180: Clock frequency (MHz.)
Experiment notes--
From file linpackup.pcsamp.m18866:
Caliper point 0 at target begin, PID 18866
/speedlin/linpack/linpackup
Caliper point 1 at exit(0)
-------------------------------------------------------------------------
Summary of statistical PC sampling data (pcsamp)--
5669: Total samples
56.690: Accumulated time (secs.)
10.0: Time per sample (msecs.)
2: Sample bin width (bytes)
-------------------------------------------------------------------------
Function list, in descending order by time
-------------------------------------------------------------------------
[index] secs % cum.% samples function (dso: file, line)
[1] 53.050 93.6% 93.6% 5305 daxpy (linpackup: linpackup.f, 495)
[2] 1.860 3.3% 96.9% 186 matgen (linpackup: linpackup.f, 199)
[3] 1.430 2.5% 99.4% 143 dgefa (linpackup: linpackup.f, 221)
[4] 0.190 0.3% 99.7% 19 idamax (linpackup: linpackup.f, 700)
[5] 0.110 0.2% 99.9% 11 dscal (linpackup: linpackup.f, 670)
[6] 0.050 0.1% 100.0% 5 dmxpy (linpackup: linpackup.f, 826)
56.690 100.0% 100.0% 5669 TOTAL |
The report has the following columns:
The index column assigns a reference number to each function.
The secs column shows the amount of CPU time spent in the routine.
The (%) column shows the percentage of the total program time that was spent in the function.
The cum.% column shows the percentage of the complete program time that has been spent by the routines listed so far.
The samples column shows how many samples were taken when the process was executing in the function.
The function (dso:file, line) columns list the routine name, its DSO name, its file name, and its line number.
| Note: This experiment can be performed only on systems that have built-in hardware counters (the R10000, R12000, R14000, and R16000 classes of machines). |
Hardware counters keep track of a variety of hardware information. For a complete list of hardware counter experiments, see the ssrun(1) man page.
This section lists the steps you need to perform a hardware counter experiment. The tutorial describes the steps involved in performing the dsc_hwc experiment. This experiment allows you to capture information about secondary data cache misses. For more information on hardware counter experiments, see “Hardware Counter Experiments (*_hwc, *_hwctime)” in Chapter 4.
From the command line, enter the following:
% ssrun -dsc_hwc linpackup |
This starts the experiment. Output from linpackup and from ssrun will be printed to stdout. A data file is also generated. The name consists of the process name (linpackup), the experiment type (dsc_hwc), and the experiment ID. In this example, the filename is linpackup.dsc_hwc.m438011.
To generate a report on the data collected, enter the following at the command line:
% prof your_output_file_name > dsc_hwc.results |
Output similar to the following is generated:
-------------------------------------------------------------------------
SpeedShop profile listing generated Mon Feb 2 13:56:59 1998
prof linpackup.dsc_hwc.m438011
linpackup (n32): Target program
dsc_hwc: Experiment name
hwc,26,131:cu: Marching orders
R10000 / R10010: CPU / FPU
16: Number of CPUs
195: Clock frequency (MHz.)
Experiment notes--
From file linpackup.dsc_hwc.m438011:
Caliper point 0 at target begin, PID 438011
/usr/demos/SpeedShop/linpack.demos/fortran/linpackup
Caliper point 1 at exit(0)
-------------------------------------------------------------------------
Summary of R10K perf. counter overflow PC sampling data (dsc_hwc)--
2929: Total samples
Sec cache D misses (26): Counter name (number)
131: Counter overflow value
383699: Total counts
-------------------------------------------------------------------------
Function list, in descending order by counts
-------------------------------------------------------------------------
[index] counts % cum.% samples function (dso: file, line)
[1] 309029 80.5% 80.5% 2359 daxpy (linpackup: linpackup.f, 495)
[2] 46636 12.2% 92.7% 356 dgefa (linpackup: linpackup.f, 221)
[3] 25938 6.8% 99.5% 198 matgen (linpackup: linpackup.f, 199)
[4] 1310 0.3% 99.8% 10 idamax (linpackup: linpackup.f, 700)
[5] 131 0.0% 99.8% 1 _FWF (libfortran.so: wf90.c, 47)
[6] 131 0.0% 99.9% 1 memset (libc.so.1: bzero.s, 98)
524 0.1% 100.0% 4 **OTHER** (includes excluded DSOs, rld, etc.)
383699 100.0% 100.0% 2929 TOTAL |
The information immediately above the function list displays the following:
The Total samples is the number of times the program counter was sampled. It is sampled once for each overflow, or each time the hardware counter exceeds the specified value.
The Counter name (number) indicates the hardware counter used in the experiment. In this case, hardware counter 26 counts the number of times a value required in a calculation was not available in secondary cache. For a complete list of the hardware counters and their numbers, see Table 4-2.
The Counter overflow value is the number at which the hardware counter overflows, or exceeds its preset value. In this case, the value is 131, which is the default. You can change the overflow value by setting the _SPEEDSHOP_HWC_COUNTER_OVERFLOW environment variable to a value larger than 0, the _SPEEDSHOP_HWC_COUNTER_NUMBER environment variable to 26, and running the prof_hwc experiment rather than dsc_hwc.
See “_hwctime Hardware Counter Experiments” in Chapter 4 to learn how to choose a counter overflow value.
The Total counts is the total number of times a value was not in secondary cache when needed. This value is determined by multiplying the total number of samples by the overflow value; extra counts that do not cause an overflow are not recorded.
The function list has the following columns:
The index column assigns a reference number to each function.
The counts column shows the number of times a data item was not in secondary cache when needed for a calculation during the execution of the routine. As with Total counts (described earlier), a routine's counts value is determined by multiplying its samples value (described later) by the overflow value.
The % column shows the percentage of the program's overflows that occurred in the routine.
The cum.% column shows the percentage of the program's overflows that occurred in the routines listed so far. For example, although the matgen routine had only 6.8% of the program's overflows, by the time it is encountered in the routine list, 99.5% of the program's total overflows have been recorded.
The samples column shows the number of times the program counter was sampled during execution of the routine. A sample is taken for each overflow of the hardware counter.
The function (dso:file, line) columns show the name, the DSO, the file name, and line number of the routine.
This section provides the steps you need to perform a bbcounts or basic block counts experiment. This experiment counts basic block usage and estimates a linear time. It also maps a complete call graph. See “Basic Block Counting Experiment (bbcounts)” in Chapter 4.
From the command line, enter the following:
% ssrun -bbcounts linpackup |
This starts the experiment. This entails making copies of the libraries and executables, giving them an extension of .pixie.
Output from linpackup and from ssrun is printed to stdout, as shown in the following example. A data file is also generated. The name consists of the process name (linpackup), the experiment type (bbcounts), and the experiment ID. In this example, the file name is linpackup.bbcounts.m77549.
instrumenting /lib32/rld instrumenting /usr/lib32/libssrt.so instrumenting /usr/lib32/libss.so instrumenting /usr/lib32/libmp.so instrumenting /usr/lib32/libftn.so instrumenting /usr/lib32/libm.so instrumenting /usr/lib32/libc.so.1 |
To generate a report on the data collected, enter the following at the command line:
% prof your_output_file_name > bbcounts.results |
The prof command redirects output to a file called bbcounts.results. The file should contain results that look something like the following.
-------------------------------------------------------------------------
SpeedShop profile listing generated Tue Mar 19 07:05:08 2002
prof linpackup.bbcounts.m18879
linpackup (n32): Target program
bbcounts: Experiment name
it:cu: Marching orders
R5000 / R5000: CPU / FPU
1: Number of CPUs
180: Clock frequency (MHz.)
Experiment notes--
From file linpackup.bbcounts.m18879:
Caliper point 0 at target begin, PID 18879
/speedlin/linpack/linpackup
Caliper point 1 at exit(0)
-------------------------------------------------------------------------
Summary of ideal time data (bbcounts)--
4947867081: Total number of instructions executed
6648387101: Total computed cycles
36.935: Total computed execution time (secs.)
1.344: Average cycles / instruction
-------------------------------------------------------------------------
Function list, in descending order by exclusive ideal time
-------------------------------------------------------------------------
[index] excl.secs excl.% cum.% cycles instructions calls function (dso: file, line)
[1] 34.620 93.7% 93.7% 6231556465 4669997342 772633 daxpy (linpackup.pixbb: linpackup.f, 495)
[2] 1.325 3.6% 97.3% 238494366 155792196 18 matgen (linpackup.pixbb: linpackup.f, 199)
[3] 0.689 1.9% 99.2% 123962402 80774803 17 dgefa (linpackup.pixbb: linpackup.f, 221)
[4] 0.138 0.4% 99.6% 24871119 18629195 5083 dscal (linpackup.pixbb: linpackup.f, 670)
[5] 0.113 0.3% 99.9% 20362634 15660094 5083 idamax (linpackup.pixbb: linpackup.f, 700)
[6] 0.029 0.1% 99.9% 5226705 3695170 1 dmxpy (linpackup.pixbb: linpackup.f, 826)
[7] 0.007 0.0% 100.0% 1204552 761974 17 dgesl (linpackup.pixbb: linpackup.f, 324)
[8] 0.004 0.0% 100.0% 710271 659913 2166 general_find_symbol (rld: rld.c, 2038)
[9] 0.003 0.0% 100.0% 490666 447076 4700 resolve_relocations (rld: rld.c, 2636)
[10] 0.001 0.0% 100.0% 239219 239219 2180 elfhash (rld: obj.c, 1184)
[11] 0.001 0.0% 100.0% 163768 163768 7126 obj_dynsym_got (rld: objfcn.c, 46)
[12] 0.001 0.0% 100.0% 157763 157763 3095 strcmp (rld: strcmp.s, 34)
[13] 0.001 0.0% 100.0% 129442 125136 2168 resolve_symbol (rld: rld.c, 1828)
[14] 0.001 0.0% 100.0% 124086 121952 2139 resolving (rld: rld.c, 1499)
[15] 0.001 0.0% 100.0% 114658 102484 2 fix_all_defineds (rld: rld.c, 3419)
[16] 0.000 0.0% 100.0% 64956 64615 7 search_for_externals (rld: rld.c, 3987)
[17] 0.000 0.0% 100.0% 61565 59304 1116 __flsbuf (libc.so.1: _flsbuf.c, 25)
[18] 0.000 0.0% 100.0% 55557 42737 4274 obj_set_dynsym_got (rld: objfcn.c, 82)
[19] 0.000 0.0% 100.0% 42595 42594 867 x_putc (libftn.so: wsfe.c, 177)
[20] 0.000 0.0% 100.0% 42261 37264 1 linp (linpackup.pixbb: linpackup.f, 3)
[21] 0.000 0.0% 100.0% 24161 21845 28 x_wEND (libftn.so: wsfe.c, 225)
[22] 0.000 0.0% 100.0% 17014 17000 8 memset (libc.so.1: bzero.s, 98)
[23] 0.000 0.0% 100.0% 14671 13537 71 do_fio64_mp (libftn.so: fmt.c, 626)
[24] 0.000 0.0% 100.0% 14575 11501 53 wrt_E (libftn.so: wrtfmt.c, 353)
.
.
.
[331] 0.000 0.0% 100.0% 1 1 1 __istart (linpackup.pixbb: crt1tinit.s, 14) |
The report has the following columns:
The index column assigns a reference number to each function.
The excl.secs column shows the minimum number of seconds that might be spent in the routine under ideal conditions.
The excl.% column represents how much of the program's total time was spent in the routine.
The cum.% column shows the cumulative percentage of time spent in the routines listed so far.
The cycles column shows the total number of machine cycles used by the routine.
The instructions column shows the total number of instructions executed by a routine.
The calls column shows the total number of calls to the routine. For example, there was just one call to the dmxpy routine.
The function (dso:file, line) column lists the name, the DSO name, the file name, and the line number for the routine.
The mpi experiment traces and times calls to MPI routines; the results are viewable with prof. The mpi_trace experiment produces the same results but the results are viewable only in cvperf.
The following steps generate tracing data for an MPI program. Before running this tutorial, you must first obtain a copy of the matmul.f file. You can perform a web search to find a downloadable copy, or go to any of the following URLS to obtain a copy of the file:
http://scv.bu.edu/SCV/Tutorials/F90/intrinsics/MATMUL.html http://www.dartmouth.edu/~rc/classes/intro_mpi/matmult.html |
Save the copy in the /usr/demos/SpeedShop directory.
First, set the MPI_RLD_HACK_OFF environment variable to prevent SpeedShop confusion over the organization of the DSOs.
% setenv MPI_RLD_HACK_OFF 1
Compile the matmul.f source file and include the MPI library:
% f90 -o matmul matmul.f -lmpi
Now run the ssrun command as part of the mpirun(1) command on the executable file to generate experiment files:
% mpirun -np 4 ssrun -mpi_trace matmul
The result will be a series of experiment files, one for each process (the identifier begins with an f) and one for the master process (the identifier begins with an m):
matmul.mpi.f9587021 matmul.mpi.f9905720 matmul.mpi.f9930637 matmul.mpi.f9930718 matmul.mpi.m9951566 Finally, display an experiment file with the WorkShop cvperf(1) command. You can use prof to display an mpi experiment and you can use cvperf to view an mpi_trace experiment.
% cvperf matmul.mpi.f9587021
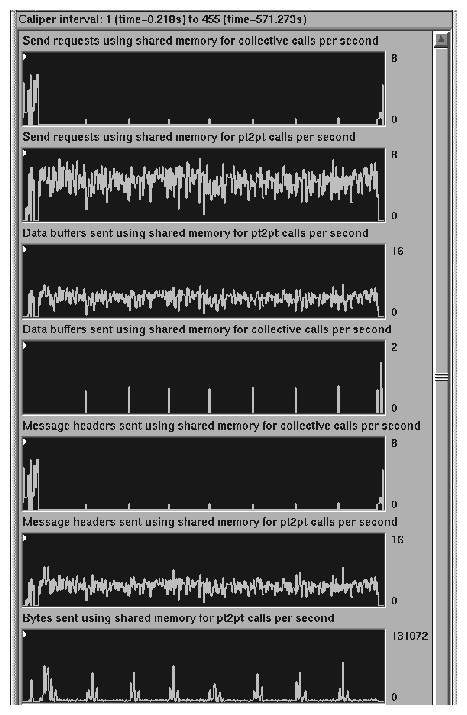
To display the output, select either MPI Stats View (Graphs) or MPI Stats View (Numerical) from the Views menu. See Figure 3-1, for an illustration of the MPI Stats View (Graphs).