This chapter describes the compiler optimization facility and how to use it. The section also contains examples demonstrating optimization techniques.
"Optimization Overview" describes the global optimizer, benefits of optimization, and debugging and optimization
"Using the Optimization Options" lists compiler optimization options and provides examples of full optimization
"Loop Optimization" explains how you can decrease execution time by optimizing loops.
"Optimizing Separate Compilation Units" covers optimization of modules
"Optimizing Frequently Used Modules" shows how optimizing frequently used modules reduces the compile and optimization time required when the modules are called
"Ucode Object Libraries" covers building and using ucode object libraries
"Improving Global Optimization" provides tips on improving optimization with examples in Fortran and C.
This section describes the compiler optimization facilities and explains their benefits, the implications of optimizing and debugging, and the major optimizing techniques. Specifically, this section explains:
The global optimizer is a single program that improves the performance of object programs by transforming existing code into more efficient coding sequences. The optimizer distinguishes between C, Pascal, and Fortran programs to take advantage of the various language semantics involved.
Silicon Graphics compilers perform both machine-independent and machine-dependent optimizations. Silicon Graphics machines and other machines with reduced instruction set computing (RISC) architectures provide a good target for both machine-independent and machine-dependent optimizations. The low-level instructions of RISC machines provide more optimization opportunities than the high-level instructions in complex instruction set computing (CISC) machines. Even optimizations that are machine-independent have been found to be more effective on machines with RISC architectures. Although most optimizations performed by the global optimizer are machine-independent, they have been specifically tailored to the Silicon Graphics environment.
The primary benefits of optimization are faster running programs and smaller object code size. However, the optimizer can also speed up development time. For example, your coding time can be reduced by leaving it up to the optimizer to relate programming details to execution time efficiency. You can focus on the more crucial global structure of your program. Moreover, programs often yield optimizable code sequences regardless of how well you write your source program.
This section lists compiler options you can use for optimization and provides examples of full optimization. Specifically, this section covers:
Invoke the optimizer by specifying a compiler driver, such as cc(1), with any of the options listed in Table 5-1.
Table 5-1. Optimization Options
 | Note: Refer to the applicable cc(1), CC(1), pc(1), or f77(1) reference pages for details on the –O3 option and the input/output files related to this option. |
Figure 5-1 shows the major processing phases of the compiler and how the compiler –On option determines the execution sequence.
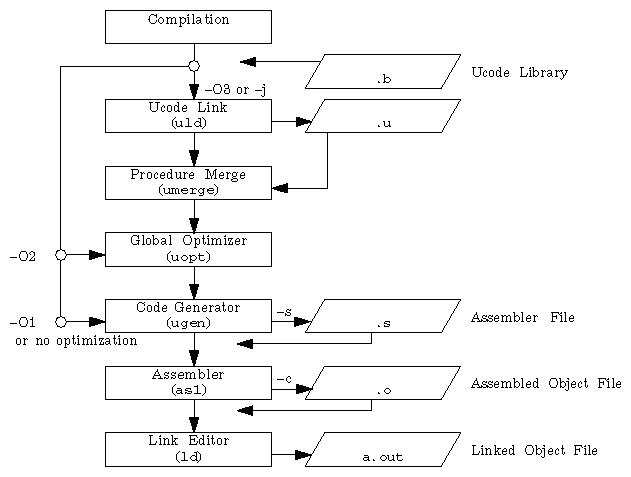
This section provides examples of full optimization using the –O3 option. Although the examples are in C, you can substitute the C files and driver command for another source language. The following examples assume that the program foo consists of three files: a.c, b.c, and c.c.
To perform procedure merging optimizations (–O3) on all three files, enter the following:
IRIS% cc -O3 -non_shared -o foo a.c b.c c.c |
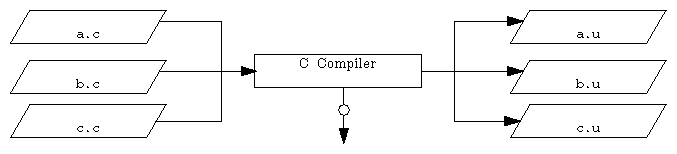
If you normally use the –c option to compile the .o object file, follow these steps:
Compile each file separately using the –j option by typing in the following:
IRIS% cc -j a.c IRIS% cc -j b.c IRIS% cc -j c.c
The –j option produces a .u file (the standard compiler front-end output made up of ucode; ucode is an internal language used by the compiler). None of the remaining compiling phases are executed, as illustrated in Figure 5-2.
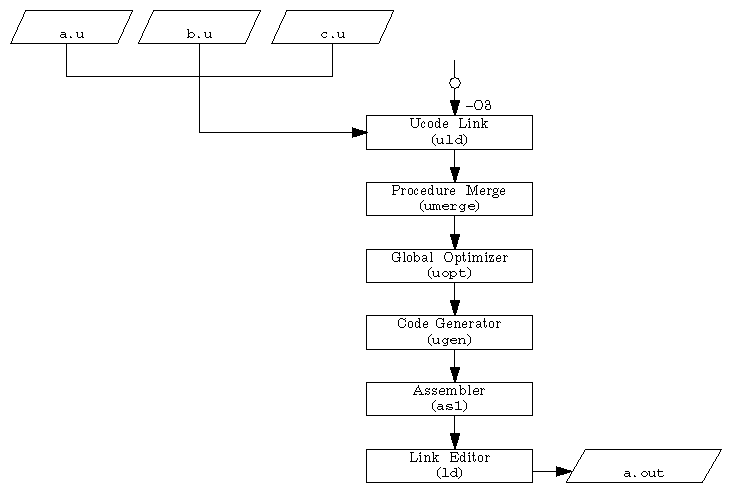
Enter the following statement to perform optimization and complete the compilation process.
IRIS% cc -O3 -non_shared -o foo a.u b.u c.u
Figure 5-3 illustrates the results of executing the above statement.
Optimizations are most useful in program areas that contain loops. The optimizer moves loop-invariant code sequences outside loops so that they are performed only once instead of multiple times. Apart from loop-invariant code, loops often contain loop-induction expressions that can be replaced with simple increments. In programs composed of mostly loops, global optimization can often reduce the running time by half.
Consider the source code below.
void left (a, distance)
char a[];
int distance;
{
int j, length;
length = strlen(a) - distance;
for (j = 0; j < length; j++)
a[j] = a[j + distance];
} |
The following code samples show the unoptimized and optimized code produced by the compiler. The optimized version (compiled with the –O option) contains fewer total instructions and fewer instructions that reference memory. Wherever possible, the optimizer replaces load and store instructions (which reference memory) with the faster computational instructions that perform operations only in registers.
The loop is 13 instructions long and uses eight memory references.
# 8 for (j=0; j<length; j++)
sw $0, 36($sp) # j = 0
ble $24, 0, $33 # length >= j
$32:
# 9 a[j] = a[j+distance];
lw $25, 36($sp) # j
lw $8, 44($sp) # distance
addu $9, $25, $8 # j+ distance
lw $10, 40(4sp) # address of a
addu $11, $10, $25 # address of a[j+distance]
lbu $12, 0($11) # a[j+distance]
addu $13, $10, $25 # address of a[j]
sb $12, 0($13) # a[j]
lw $14, 36($sp) # j
addu $15, $14, 1 # j+1
sw $15, 36($sp) # j++
lw $3, 32($sp) # length
blt $15, $3, $32 # j < length
$33: |
The loop is six instructions long and uses two memory references.
# 8 for (j=0; j<length; j++)
move $5,$0 # j = 0
ble $4, 0, $33 # length >= j
move $2, $16 # address of a[j]
addu $6, $16, $1 # address of a[j+distance]
$32:
# 9 a[j] = a[j+distance];
lbu $3, 0($6) # a[j+distance]
sb $3, 0($2) # a[j]
addu $5, $5, 1 # j++
addu $2, $2, 1 # address of next a[j]
addu $6, $6, 1 # address of next a[j+distance]
blt $5, $4, $32 # j < length
$33: # address of next a[j+distance] |
The optimizer performs loop unrolling to improve performance in two ways:
Reduces loop overhead.
Increases work performed in the larger loop body allowing more opportunity for optimization and register usage.
For example, the Fortran loop:
do i=1,100 sum = sum + a(i)*b(i) enddo |
when unrolled four times looks like
do i=1,100,4 sum = sum + a(i)*b(i) sum = sum + a(i+1)*b(i+1) sum = sum + a(i+2)*b(i+2) sum = sum + a(i+3)*b(i+3) enddo |
The unrolled version runs much faster than the original. Most of the increase in execution speed is due to the overlapping of multiplication and addition operations. The optimizer performs this transformation on its own internal representation of the program, not by rewriting the original source code.
| Note: If the number of iterations of the loop is not an exact multiple of the unrolling factor (or if the number of iterations is unknown), the optimizer still performs this transformation even though the resultant code is more complicated than the original code. |
The uld and umerge phases of the compiler permit global optimization among code from separate files (or "modules") in the same compilation. Traditionally, program modularity restricted the optimization of code to a single compilation unit at a time rather than over the full breadth of the program. For example, it was impossible to fully optimize calling code along with the procedures called if those procedures resided in other modules.
The uld and umerge phases of the compiler system overcome this deficiency. The uld phase links multiple modules into a single unit. Then, umerge orders the procedures for optimal processing by the global optimizer, uopt.
Compiling and optimizing frequently used modules reduces the compile and optimization time required when the modules are called.
The following procedure explains how to compile two frequently used modules, b.c and c.c, while retaining all the necessary information to link them with future programs; future.c represents one such program.
Compile b.c and c.c separately by entering the following statements:
IRIS% cc -j b.c IRIS% cc -j c.c
The –j option causes the front end (first phase) of the compiler to produce two ucode files: b.u and c.u.
Using an editor, create a file containing the external symbols in b.c and c.c to which future.c will refer. Each symbolic name must be separated by at least one blank. Consider the skeletal contents of b.c and c.c:
File b.c File c.c foo() x() { { . . . . } } bar() help() { { . . . . zot() } { . struct . { } . . struct } ddata; { . y() . { } work; . } . }In this example, future.c calls or references only foo, bar, x, ddata, and y in the b.c and c.c procedures. A file (named extern for this example) must be created containing the following symbolic names:
foo bar x ddata y
The structure work, and the procedures help and zot are used internally only by b.c and c.c, and thus are not included in extern.
If you omit an external symbolic name, an error message is generated (see Step 4 below).
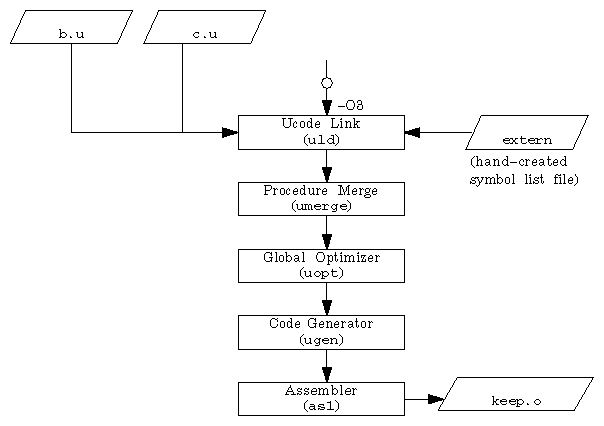
Optimize the b.u and c.u modules (created in Step 1) using the extern file (created in Step 2) as follows:
IRIS% cc -O3 -non_shared -rm_dead_code -kp extern b.u c.u -o keep.o -c
The –rm_dead_code option tells the linker to assume names not specified in the extern file as internal names. In the –kp option, k indicates that the linker option –p is to be passed to the ucode loader. The –c option suppresses the a.out file.
Figure 5-4 illustrates the optimization process in Step 3.
Create a ucode file and an optimized object code file (foo) for future.c as follows:
IRIS% cc -j future.c IRIS% cc -O3 -non_shared future.u keep.o -o foo
If the following message appears it means that the code in future.c is using a symbol from the code in b.c or c.c that was not specified in the file extern (go to Step 5 if this message appears.)
zot: multiply defined hidden external (should have been preserved)
Include zot, which the message indicates is missing, in the file extern and recompile as follows:
IRIS% cc -O3 -non_shared -kp extern b.u c.u -o keep.o IRIS% cc -O3 -non_shared future.u keep.o -o foo
This section describes how to build and use ucode object libraries.
Building ucode object libraries is similar to building coff(5) object libraries. First, compile the source files into ucode object files using the compiler driver option –j and using the archiver just as you would for coff object libraries.
Using the above example, to build a ucode library (libfoo.b) of a source file, enter the following:
IRIS% cc -j a.c IRIS% cc -j b.c IRIS% cc -j c.c IRIS% ar crs libfoo.b a.u b.u c.u |
Conventional names exist for ucode object libraries (libname.b) just as they do for coff object libraries (libname.a).
Using ucode object libraries is similar to using coff(5) object files. To load from a ucode library, specify a –klname option to the compiler driver or the ucode loader. For example, to load the file created in the previous example from the ucode library (assuming libfoo.a was placed in the /usr/lib directory), enter the following:
IRIS% cc -O3 -non_shared file1.u file2.u -klfoo -o output |
Remember that libraries are searched as they are encountered on the command line, so the order in which you specify them is important. If a library is made from both assembly and high-level language routines, the ucode object library contains code only for the high-level language routines. The library does not contain all the routines, as does a coff object library or a DSO. In this case, specify to the ucode loader first the ucode object library and then the coff object library or DSO to ensure that all modules are loaded from the proper library.
If the compiler driver is to perform both a ucode load step and a final load step, the object file created after the ucode load step is placed in the position of the first ucode file specified or created on the command line in the final load step.
This section describes coding hints that increase optimizing opportunities for the global optimizer (uopt). Apply these recommendations to your code whenever possible. Topics include:
The following suggestion applies to both C and Fortran programs:
Do not use indirect calls (calls that use routines or pointers to functions as arguments). Indirect calls cause unknown side effects (that is, they change global variables) that can reduce the amount of optimization possible.
The following suggestions apply to C programs only:
Return values. Use functions that return values instead of pointer parameters.
Do while. When possible, use do while instead of while or for. For do while, the optimizer does not have to duplicate the loop condition in order to move code from within the loop to outside the loop.
Unions. Avoid unions that cause overlap between integer and floating point data types. The optimizer does not assign such fields to registers.
Use local variables. Avoid global variables. In C programs, declare any variable outside of a function as static, unless that variable is referenced by another source file. Minimizing the use of global variables increases optimization opportunities for the compiler.
Value parameters. Pass parameters by value instead of passing by reference (pointers) or using global variables. Reference parameters have the same degrading effects as the use of pointers (see below).
Pointers and aliasing.Aliases occur when there are multiple ways to reference the same data object. For instance, when the address of a global variable is passed as a subprogram argument, it may be referenced either using its global name, or via the pointer. The compiler must be conservative when dealing with objects that may be aliased, for instance keeping them in memory instead of in registers, and carefully retaining the original source program order for possibly aliased references.
Pointers in particular tend to cause aliasing problems, since it is often impossible for the compiler to identify their target objects. Therefore, you can help the compiler avoid possible aliases by introducing local variables to store the values obtained from dereferenced pointers. Indirect operations and calls affect dereferenced values, but do not affect local variables. Therefore, local variables can be kept in registers. The following example shows how the proper placement of pointers and the elimination of aliasing produces better code.
In the example below, if len>10 (for instance because it is changed in another function before calling zero), *p++ = 0 will eventually modify len. Therefore, the compiler cannot place len in a register for optimal performance. Instead, the compiler must load it from memory on each pass through the loop.
Consider the following source code:
char a[10];
int len = 10;
void
zero()
{
char *p;
for (p= a; p != a + len; ) *p++ = 0;
} |
The generated assembly code looks like this:
#8 for (p = a; p!= a + len; ) *p++ = 0;
move $2, $4
lw $3, len
addu $24, $4, $3
beq $24 $4 $33 # a + len != p
$32:
sb $0, 0($2) # *p = 0
addu $2, $2, 1 # p++
lw $25, len
addu $8, $4, $25
bne $8, $2, $32 # a + len != p
$33: |
You can increase the efficiency of this example by using subscripts instead of pointers, or by using local variables to store unchanging values.
Using subscripts instead of pointers. Using subscripts in the procedure azero (as shown below) eliminates aliasing. The compiler keeps the value of len in a register, saving two instructions. It still uses a pointer to access a efficiently, even though a pointer is not specified in the source code. For example, consider the following source code:
char a[10];
int len = 10;
void azero()
{
int i;
for ( i = 0; i != len; i++ )
a[i] = 0;
} |
The generated assembly code looks like this:
for (i = 0; i != len; i++ ) a[i] = 0;
move $2, $0 # i = 0
beq $4, 0, $37 # len != a
la $5, a
$36:
sb $0, 0($5) # *a = 0
addu $2, $2, 1 # i++
addu $5, $5, 1 # a++
bne $2, $4, $36 # i != len
$37: |
Using local variables. Using local (automatic) variables or formal arguments instead of static or global prevents aliasing and allows the compiler to allocated them in registers.
For example, in the following code fragment, the variables loc and form are likely to be more efficient than ext* and stat*.
extern int ext1;
static int stat1;
void p ( int form )
{
extern int ext2;
static int stat2;
int loc;
...
} |
Write straightforward code. For example, do not use ++ and -- operators within an expression. Using these operators for their values, rather than for their side-effects, often produces bad code.
Addresses. Avoid taking and passing addresses (& values). Using addresses creates aliases, makes the optimizer store variables from registers to their home storage locations, and significantly reduces optimization opportunities that would otherwise be performed by the compiler.
VARARG/STDARG. Avoid functions that take a variable number of arguments. The optimizer saves all parameter registers on entry to VARARG or STDARG functions. If you must use these functions, use the ANSI standard facilities of stdarg.h. These produce simpler code than the older version of varargs.h
The global optimizer processes programs only when you specify the –O2 or –O3 option at compilation. However, the code generator and assembler phases of the compiler always perform certain optimizations (certain assembler optimizations are bypassed when you specify the –O0 option at compilation).
This section contains coding hints that increase optimizing opportunities for the other passes of the compiler.
The following suggestions apply to both C and Fortran programs:
Use tables rather than if-then-else or switch statements. For example:
typedef enum { BLUE, GREEN, RED, NCOLORS } COLOR;Instead of:
switch ( c ) { case CASE0: x = 5; break; case CASE1: x = 10; break; case CASE2: x = 1; break; }Use:
static int Mapping[NCOLORS] = { 5, 10, 1 }; ... x = Mapping[c];As an optimizing technique, the compiler puts the first eight parameters of a parameter list into registers where they may remain during execution of the called routine. Therefore, always declare, as the first eight parameters, those variables that are most frequently manipulated in the called routine.
Use word-size scalar variables instead of smaller ones. This practice can take more data space, but produces more efficient code.
The following suggestions apply to C programs only:
Rely on libc.so functions (for example, strcpy, strlen, strcmp, bcopy, bzero, memset, and memcpy). These functions were carefully coded for efficiency.
Use the unsigned data type for variables wherever possible (see next bulleted item for an exception to this rule, though). The compiler generates fewer instructions for multiplying and dividing unsigned numbers by a power of two. Consider the following example:
int i; unsigned j; ... return i/2 + j/2;
The compiler generates six instructions for the signed i/2 operation:
000000 20010002 li r1,2 000004 0081001a div r4,r1 000008 14200002 bne r1,r0,0x14 00000c 00000000 nop 000010 03fe000d break 1022 000014 00001812 mflo r3
The compiler generates only one instruction for the unsigned j/2 operation:
000018 0005c042 srl r24,r5,1 # j / 2
In this example, i/2 is an expensive expression, while j/2 is inexpensive.
Use a signed data type, or cast to a signed data type, for any variable which must be converted to floating-point.
double d; unsigned int u; int i; /* fast */ d = i; /* fast */ d = (int)u; /* slow */ d = u;
Converting an unsigned type to floating-point takes significantly longer than converting signed types to floating-point; additional software support must be generated in the instruction stream for the former case.
The MIPS architecture emphasizes the use of registers. Therefore, register usage has a significant impact on program performance.
The optimizer allocates registers for the most suitable data items, taking into account their frequency of use and their locations in the program structure. Also, the optimizer assigns values to registers in such a way as to minimize movement of values among registers during procedure invocations.